Introducing Self-Evolving Agent Memory: How EverOS Helps Your AI Agents Learn from Experience
Introducing Self-Evolving Agent Memory: How EverOS Helps Your AI Agents Learn from Experience
This post explains what Agent Memory is, how it works, and what it means for building agents that actually improve over time.
EverMind researchers
About 3 minutes to read

Most AI agents are stuck in a loop. They complete a task, and then they forget everything about how they did it. The next time they face the same problem, they start from scratch — same reasoning process, same trial and error, same mistakes. They never get better.
EverOS Agent Memory changes this. It gives your agents a structured way to record what they did, learn what worked, and build on that knowledge the next time a similar task comes up.
This post explains what Agent Memory is, how it works, and what it means for building agents that actually improve over time.
The difference between User Memory and Agent Memory
EverOS already builds persistent memory from conversations — tracking what users say, what they prefer, and who they are over time. That's User Memory: its purpose is to make agents more personal and context-aware.
Agent Memory is a different thing entirely. Its purpose is not to understand the user better. Its purpose is to make the agent itself smarter.
When an agent completes a task — researching options, writing code, solving a multi-step problem — the trajectory of how it did that contains valuable information. Which tool calls worked. Which approaches failed. How a complex problem was decomposed. What the outcome was. That information is exactly what a future agent could use to tackle a similar task faster and more reliably.
Agent Memory captures that information, structures it, and makes it retrievable. An agent that has processed hundreds of tasks doesn't start from scratch on task 101. It draws on accumulated experience.
What gets recorded
When you send agent trajectories to EverOS — including the full sequence of reasoning steps, tool calls, tool responses, and final answers — the system processes them into two types of structured memory.
Agent Cases
An Agent Case is a record of a specific task execution. It captures:
Task intent — what the agent was actually trying to accomplish, expressed as a clear, self-contained statement. This serves as the retrieval key when a future agent is facing something similar.
Approach — a compressed record of how the agent solved the problem. The approach is organized by sub-problems: for each step, what was attempted, what tool was used or what reasoning was applied, and what resulted. If an attempt failed and required revision, that's recorded too. The approach ends with an Outcome that summarizes the final result.
Quality score — a self-assessed score from 0 to 1 reflecting how well the agent completed the task.
Here's what a real Agent Case looks like, from a coding agent that implemented rate limiting middleware:
Task intent: Implement rate limiting middleware for a FastAPI API with default 100 requests per minute per IP, with per-endpoint overrides for /api/auth/login and unlimited /api/health.
Approach:
1. Read existing middleware setup
- Tried: read_file on src/middleware/__init__
Agent Skills
Agent Cases record specific executions. Agent Skills are what emerges when cases are consolidated.
As cases accumulate around a recurring theme — multiple agents solving database comparison problems, multiple sessions implementing API validation — EverOS clusters them and distills the shared patterns into a Skill. A Skill is a generalized, reusable best-practice process: when to apply it, what steps to follow, and what pitfalls to avoid based on failed attempts that came before.
A Skill generated from search agent cases solving framework comparison tasks might look like this:
Skill: Compare Software Tools by Suitability and Performance When to use: When evaluating databases, frameworks, or libraries for specific use cases based on suitability, performance benchmarks, and metrics. Steps: 1. Search for top candidates using web_search with query '[use case] best [tool type] [key requirement] [year] comparison'. 2. Search for performance benchmarks with '[top candidates] benchmark [key metrics] [year]
Skills are not locked to a single agent or session. Any agent operating within the same namespace can retrieve and apply them. What one agent learned, every future agent can benefit from.
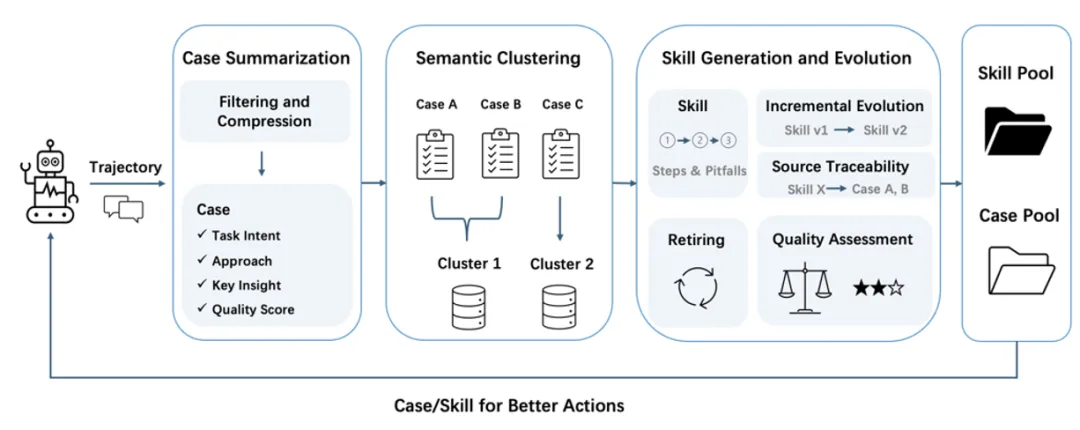
How agent trajectories are processed
The raw output of an agent — a long sequence of user messages, assistant reasoning, tool calls, and tool responses — is not directly stored. Long trajectories are compressed before extraction.
For very long trajectories, EverOS applies a pre-compression strategy that combines heuristic rules with LLM-based compression to reduce noise and improve long-context processing. This mechanism is designed to help EverOS efficiently handle extended trajectories while preserving overall coherence.
After compression, the system evaluates whether the trajectory is worth storing as a case at all. Casual chat, simple Q&A, and non-task interactions are filtered out. Only goal-directed agent work, where the agent was actually trying to accomplish something, gets distilled into a case.
Once cases accumulate within a topic cluster, Skill generation is triggered. The system considers all existing Skills before generating new ones — merging similar patterns rather than creating redundant variants. Skills are validated before becoming retrievable, ensuring only sufficiently mature and reliable knowledge gets surfaced to future agents.
How agents use their memory
When a future agent takes on a task, it can search the Agent Memory namespace before starting. The search uses the task intent as a query, retrieving:
Similar agent cases — showing how past agents approached comparable problems, including which sub-steps they took and what outcomes they achieved
Relevant skills — providing generalizable best-practice processes directly applicable to the current task
This means an agent building a Docker deployment guide doesn't derive the approach from scratch. It retrieves the pattern from agents that did this before: search official docs, identify the essential components, synthesize into an actionable example, include production tips. The reasoning is already there.
A search agent evaluating databases doesn't re-learn which sources are reliable or how to structure a comparison. A coding agent implementing middleware doesn't re-discover how to read existing code structure before writing new files. They draw on the accumulated experience of every prior agent that ran before them.
Works across agent types
Agent Memory is not specific to any particular kind of agent. In demos across three different agent architectures, the same memory system produced useful cases and skills in every scenario:
A search agent doing web research produced cases capturing comparison and recommendation workflows, and skills for structured tool selection and Docker deployment guidance.
A coding agent doing implementation work produced cases capturing the full read-code, implement, test, iterate cycle, and skills for Pydantic validation patterns and middleware design.
A chat agent handling personalization produced cases capturing the iterative refinement approach to recommendations, and skills for structuring category-based suggestions.
The agent type changes. The memory structure and the mechanism for learning from it stay the same.
Multi-agent systems and shared memory
A single agent accumulates experience. Since each trajectory is stored independently, multiple agents sharing the same memory namespace can collectively build up a larger pool of cases and skills over time.
In a multi-agent system — where a planning agent, a research agent, and a writing agent are all working on behalf of the same user — each agent's cases and skills are searchable by all the others. What the research agent learned about structured tool use may be retrieved when the planning agent approaches a similar information-gathering task. Skills generalize across roles.
For main-sub agent architectures, where one agent delegates tasks to specialized sub-agents as tool calls, the sub-agent trajectories can each be logged and stored as individual cases. The learning from delegation is preserved, not lost.
How to use it
Send your agent trajectory to EverOS using the agent endpoint:
POST /api/v1/memories/agent
{ "user_id": "user_123", "session_id": "session_456", "messages": [ { "role": "user", "content": "Implement rate limiting for the FastAPI app", "timestamp": 1740000000000 }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "call_001", "function": { "name": "read_file", "arguments": "{\"path\": \"src/middleware/__init__.py\"}" } } ], "timestamp": 1740000001000 }, { "role": "tool", "tool_call_id": "call_001", "content": "MIDDLEWARE_STACK = [CORSMiddleware, LoggingMiddleware]", "timestamp": 1740000002000 } // ... rest of trajectory ] }
The trajectory is processed asynchronously. Once extracted, the agent case is retrievable via a search request:
POST /api/v1/memories/search
{ "query": "implement rate limiting FastAPI middleware", "memory_types": ["agent_memory"], "filters": { "user_id": "user_123" } }
The response includes both cases and skills under the agent_memory field.
What this means for how agents develop
The standard model for improving an AI agent is to retrain it, fine-tune it, or write better prompts. These are valuable, but they're all changes to the agent itself — and they're expensive, slow, and not specific to the tasks your agents are actually doing in production.
Agent Memory is a different lever. It doesn't change the model. It gives the model access to a growing body of structured, task-specific experience that gets better the more your agents run. The first time an agent solves a problem, it figures it out. The tenth time, there's a skill for it.
Agents that use their own accumulated experience are faster, more reliable, and more consistent. They avoid repeating known mistakes. They don't re-derive patterns that have already been established. They compound instead of cycling.
That is what it means for an agent to actually learn from experience.
Agent Memory is available now on EverOS. To get started: everos.evermind.ai
Open-source repository: github.com/EverMind-AI/EverOS
Most AI agents are stuck in a loop. They complete a task, and then they forget everything about how they did it. The next time they face the same problem, they start from scratch — same reasoning process, same trial and error, same mistakes. They never get better.
EverOS Agent Memory changes this. It gives your agents a structured way to record what they did, learn what worked, and build on that knowledge the next time a similar task comes up.
This post explains what Agent Memory is, how it works, and what it means for building agents that actually improve over time.
The difference between User Memory and Agent Memory
EverOS already builds persistent memory from conversations — tracking what users say, what they prefer, and who they are over time. That's User Memory: its purpose is to make agents more personal and context-aware.
Agent Memory is a different thing entirely. Its purpose is not to understand the user better. Its purpose is to make the agent itself smarter.
When an agent completes a task — researching options, writing code, solving a multi-step problem — the trajectory of how it did that contains valuable information. Which tool calls worked. Which approaches failed. How a complex problem was decomposed. What the outcome was. That information is exactly what a future agent could use to tackle a similar task faster and more reliably.
Agent Memory captures that information, structures it, and makes it retrievable. An agent that has processed hundreds of tasks doesn't start from scratch on task 101. It draws on accumulated experience.
What gets recorded
When you send agent trajectories to EverOS — including the full sequence of reasoning steps, tool calls, tool responses, and final answers — the system processes them into two types of structured memory.
Agent Cases
An Agent Case is a record of a specific task execution. It captures:
Task intent — what the agent was actually trying to accomplish, expressed as a clear, self-contained statement. This serves as the retrieval key when a future agent is facing something similar.
Approach — a compressed record of how the agent solved the problem. The approach is organized by sub-problems: for each step, what was attempted, what tool was used or what reasoning was applied, and what resulted. If an attempt failed and required revision, that's recorded too. The approach ends with an Outcome that summarizes the final result.
Quality score — a self-assessed score from 0 to 1 reflecting how well the agent completed the task.
Here's what a real Agent Case looks like, from a coding agent that implemented rate limiting middleware:
Task intent: Implement rate limiting middleware for a FastAPI API with default 100 requests per minute per IP, with per-endpoint overrides for /api/auth/login and unlimited /api/health.
Approach:
1. Read existing middleware setup
- Tried: read_file on src/middleware/__init__
Agent Skills
Agent Cases record specific executions. Agent Skills are what emerges when cases are consolidated.
As cases accumulate around a recurring theme — multiple agents solving database comparison problems, multiple sessions implementing API validation — EverOS clusters them and distills the shared patterns into a Skill. A Skill is a generalized, reusable best-practice process: when to apply it, what steps to follow, and what pitfalls to avoid based on failed attempts that came before.
A Skill generated from search agent cases solving framework comparison tasks might look like this:
Skill: Compare Software Tools by Suitability and Performance When to use: When evaluating databases, frameworks, or libraries for specific use cases based on suitability, performance benchmarks, and metrics. Steps: 1. Search for top candidates using web_search with query '[use case] best [tool type] [key requirement] [year] comparison'. 2. Search for performance benchmarks with '[top candidates] benchmark [key metrics] [year]
Skills are not locked to a single agent or session. Any agent operating within the same namespace can retrieve and apply them. What one agent learned, every future agent can benefit from.
How agent trajectories are processed
The raw output of an agent — a long sequence of user messages, assistant reasoning, tool calls, and tool responses — is not directly stored. Long trajectories are compressed before extraction.
For very long trajectories, EverOS applies a pre-compression strategy that combines heuristic rules with LLM-based compression to reduce noise and improve long-context processing. This mechanism is designed to help EverOS efficiently handle extended trajectories while preserving overall coherence.
After compression, the system evaluates whether the trajectory is worth storing as a case at all. Casual chat, simple Q&A, and non-task interactions are filtered out. Only goal-directed agent work, where the agent was actually trying to accomplish something, gets distilled into a case.
Once cases accumulate within a topic cluster, Skill generation is triggered. The system considers all existing Skills before generating new ones — merging similar patterns rather than creating redundant variants. Skills are validated before becoming retrievable, ensuring only sufficiently mature and reliable knowledge gets surfaced to future agents.
How agents use their memory
When a future agent takes on a task, it can search the Agent Memory namespace before starting. The search uses the task intent as a query, retrieving:
Similar agent cases — showing how past agents approached comparable problems, including which sub-steps they took and what outcomes they achieved
Relevant skills — providing generalizable best-practice processes directly applicable to the current task
This means an agent building a Docker deployment guide doesn't derive the approach from scratch. It retrieves the pattern from agents that did this before: search official docs, identify the essential components, synthesize into an actionable example, include production tips. The reasoning is already there.
A search agent evaluating databases doesn't re-learn which sources are reliable or how to structure a comparison. A coding agent implementing middleware doesn't re-discover how to read existing code structure before writing new files. They draw on the accumulated experience of every prior agent that ran before them.
Works across agent types
Agent Memory is not specific to any particular kind of agent. In demos across three different agent architectures, the same memory system produced useful cases and skills in every scenario:
A search agent doing web research produced cases capturing comparison and recommendation workflows, and skills for structured tool selection and Docker deployment guidance.
A coding agent doing implementation work produced cases capturing the full read-code, implement, test, iterate cycle, and skills for Pydantic validation patterns and middleware design.
A chat agent handling personalization produced cases capturing the iterative refinement approach to recommendations, and skills for structuring category-based suggestions.
The agent type changes. The memory structure and the mechanism for learning from it stay the same.
Multi-agent systems and shared memory
A single agent accumulates experience. Since each trajectory is stored independently, multiple agents sharing the same memory namespace can collectively build up a larger pool of cases and skills over time.
In a multi-agent system — where a planning agent, a research agent, and a writing agent are all working on behalf of the same user — each agent's cases and skills are searchable by all the others. What the research agent learned about structured tool use may be retrieved when the planning agent approaches a similar information-gathering task. Skills generalize across roles.
For main-sub agent architectures, where one agent delegates tasks to specialized sub-agents as tool calls, the sub-agent trajectories can each be logged and stored as individual cases. The learning from delegation is preserved, not lost.
How to use it
Send your agent trajectory to EverOS using the agent endpoint:
POST /api/v1/memories/agent
{ "user_id": "user_123", "session_id": "session_456", "messages": [ { "role": "user", "content": "Implement rate limiting for the FastAPI app", "timestamp": 1740000000000 }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "call_001", "function": { "name": "read_file", "arguments": "{\"path\": \"src/middleware/__init__.py\"}" } } ], "timestamp": 1740000001000 }, { "role": "tool", "tool_call_id": "call_001", "content": "MIDDLEWARE_STACK = [CORSMiddleware, LoggingMiddleware]", "timestamp": 1740000002000 } // ... rest of trajectory ] }
The trajectory is processed asynchronously. Once extracted, the agent case is retrievable via a search request:
POST /api/v1/memories/search
{ "query": "implement rate limiting FastAPI middleware", "memory_types": ["agent_memory"], "filters": { "user_id": "user_123" } }
The response includes both cases and skills under the agent_memory field.
What this means for how agents develop
The standard model for improving an AI agent is to retrain it, fine-tune it, or write better prompts. These are valuable, but they're all changes to the agent itself — and they're expensive, slow, and not specific to the tasks your agents are actually doing in production.
Agent Memory is a different lever. It doesn't change the model. It gives the model access to a growing body of structured, task-specific experience that gets better the more your agents run. The first time an agent solves a problem, it figures it out. The tenth time, there's a skill for it.
Agents that use their own accumulated experience are faster, more reliable, and more consistent. They avoid repeating known mistakes. They don't re-derive patterns that have already been established. They compound instead of cycling.
That is what it means for an agent to actually learn from experience.
Agent Memory is available now on EverOS. To get started: everos.evermind.ai
Open-source repository: github.com/EverMind-AI/EverOS
Most AI agents are stuck in a loop. They complete a task, and then they forget everything about how they did it. The next time they face the same problem, they start from scratch — same reasoning process, same trial and error, same mistakes. They never get better.
EverOS Agent Memory changes this. It gives your agents a structured way to record what they did, learn what worked, and build on that knowledge the next time a similar task comes up.
This post explains what Agent Memory is, how it works, and what it means for building agents that actually improve over time.
The difference between User Memory and Agent Memory
EverOS already builds persistent memory from conversations — tracking what users say, what they prefer, and who they are over time. That's User Memory: its purpose is to make agents more personal and context-aware.
Agent Memory is a different thing entirely. Its purpose is not to understand the user better. Its purpose is to make the agent itself smarter.
When an agent completes a task — researching options, writing code, solving a multi-step problem — the trajectory of how it did that contains valuable information. Which tool calls worked. Which approaches failed. How a complex problem was decomposed. What the outcome was. That information is exactly what a future agent could use to tackle a similar task faster and more reliably.
Agent Memory captures that information, structures it, and makes it retrievable. An agent that has processed hundreds of tasks doesn't start from scratch on task 101. It draws on accumulated experience.
What gets recorded
When you send agent trajectories to EverOS — including the full sequence of reasoning steps, tool calls, tool responses, and final answers — the system processes them into two types of structured memory.
Agent Cases
An Agent Case is a record of a specific task execution. It captures:
Task intent — what the agent was actually trying to accomplish, expressed as a clear, self-contained statement. This serves as the retrieval key when a future agent is facing something similar.
Approach — a compressed record of how the agent solved the problem. The approach is organized by sub-problems: for each step, what was attempted, what tool was used or what reasoning was applied, and what resulted. If an attempt failed and required revision, that's recorded too. The approach ends with an Outcome that summarizes the final result.
Quality score — a self-assessed score from 0 to 1 reflecting how well the agent completed the task.
Here's what a real Agent Case looks like, from a coding agent that implemented rate limiting middleware:
Task intent: Implement rate limiting middleware for a FastAPI API with default 100 requests per minute per IP, with per-endpoint overrides for /api/auth/login and unlimited /api/health.
Approach:
1. Read existing middleware setup
- Tried: read_file on src/middleware/__init__
Agent Skills
Agent Cases record specific executions. Agent Skills are what emerges when cases are consolidated.
As cases accumulate around a recurring theme — multiple agents solving database comparison problems, multiple sessions implementing API validation — EverOS clusters them and distills the shared patterns into a Skill. A Skill is a generalized, reusable best-practice process: when to apply it, what steps to follow, and what pitfalls to avoid based on failed attempts that came before.
A Skill generated from search agent cases solving framework comparison tasks might look like this:
Skill: Compare Software Tools by Suitability and Performance When to use: When evaluating databases, frameworks, or libraries for specific use cases based on suitability, performance benchmarks, and metrics. Steps: 1. Search for top candidates using web_search with query '[use case] best [tool type] [key requirement] [year] comparison'. 2. Search for performance benchmarks with '[top candidates] benchmark [key metrics] [year]
Skills are not locked to a single agent or session. Any agent operating within the same namespace can retrieve and apply them. What one agent learned, every future agent can benefit from.
How agent trajectories are processed
The raw output of an agent — a long sequence of user messages, assistant reasoning, tool calls, and tool responses — is not directly stored. Long trajectories are compressed before extraction.
For very long trajectories, EverOS applies a pre-compression strategy that combines heuristic rules with LLM-based compression to reduce noise and improve long-context processing. This mechanism is designed to help EverOS efficiently handle extended trajectories while preserving overall coherence.
After compression, the system evaluates whether the trajectory is worth storing as a case at all. Casual chat, simple Q&A, and non-task interactions are filtered out. Only goal-directed agent work, where the agent was actually trying to accomplish something, gets distilled into a case.
Once cases accumulate within a topic cluster, Skill generation is triggered. The system considers all existing Skills before generating new ones — merging similar patterns rather than creating redundant variants. Skills are validated before becoming retrievable, ensuring only sufficiently mature and reliable knowledge gets surfaced to future agents.
How agents use their memory
When a future agent takes on a task, it can search the Agent Memory namespace before starting. The search uses the task intent as a query, retrieving:
Similar agent cases — showing how past agents approached comparable problems, including which sub-steps they took and what outcomes they achieved
Relevant skills — providing generalizable best-practice processes directly applicable to the current task
This means an agent building a Docker deployment guide doesn't derive the approach from scratch. It retrieves the pattern from agents that did this before: search official docs, identify the essential components, synthesize into an actionable example, include production tips. The reasoning is already there.
A search agent evaluating databases doesn't re-learn which sources are reliable or how to structure a comparison. A coding agent implementing middleware doesn't re-discover how to read existing code structure before writing new files. They draw on the accumulated experience of every prior agent that ran before them.
Works across agent types
Agent Memory is not specific to any particular kind of agent. In demos across three different agent architectures, the same memory system produced useful cases and skills in every scenario:
A search agent doing web research produced cases capturing comparison and recommendation workflows, and skills for structured tool selection and Docker deployment guidance.
A coding agent doing implementation work produced cases capturing the full read-code, implement, test, iterate cycle, and skills for Pydantic validation patterns and middleware design.
A chat agent handling personalization produced cases capturing the iterative refinement approach to recommendations, and skills for structuring category-based suggestions.
The agent type changes. The memory structure and the mechanism for learning from it stay the same.
Multi-agent systems and shared memory
A single agent accumulates experience. Since each trajectory is stored independently, multiple agents sharing the same memory namespace can collectively build up a larger pool of cases and skills over time.
In a multi-agent system — where a planning agent, a research agent, and a writing agent are all working on behalf of the same user — each agent's cases and skills are searchable by all the others. What the research agent learned about structured tool use may be retrieved when the planning agent approaches a similar information-gathering task. Skills generalize across roles.
For main-sub agent architectures, where one agent delegates tasks to specialized sub-agents as tool calls, the sub-agent trajectories can each be logged and stored as individual cases. The learning from delegation is preserved, not lost.
How to use it
Send your agent trajectory to EverOS using the agent endpoint:
POST /api/v1/memories/agent
{ "user_id": "user_123", "session_id": "session_456", "messages": [ { "role": "user", "content": "Implement rate limiting for the FastAPI app", "timestamp": 1740000000000 }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "call_001", "function": { "name": "read_file", "arguments": "{\"path\": \"src/middleware/__init__.py\"}" } } ], "timestamp": 1740000001000 }, { "role": "tool", "tool_call_id": "call_001", "content": "MIDDLEWARE_STACK = [CORSMiddleware, LoggingMiddleware]", "timestamp": 1740000002000 } // ... rest of trajectory ] }
The trajectory is processed asynchronously. Once extracted, the agent case is retrievable via a search request:
POST /api/v1/memories/search
{ "query": "implement rate limiting FastAPI middleware", "memory_types": ["agent_memory"], "filters": { "user_id": "user_123" } }
The response includes both cases and skills under the agent_memory field.
What this means for how agents develop
The standard model for improving an AI agent is to retrain it, fine-tune it, or write better prompts. These are valuable, but they're all changes to the agent itself — and they're expensive, slow, and not specific to the tasks your agents are actually doing in production.
Agent Memory is a different lever. It doesn't change the model. It gives the model access to a growing body of structured, task-specific experience that gets better the more your agents run. The first time an agent solves a problem, it figures it out. The tenth time, there's a skill for it.
Agents that use their own accumulated experience are faster, more reliable, and more consistent. They avoid repeating known mistakes. They don't re-derive patterns that have already been established. They compound instead of cycling.
That is what it means for an agent to actually learn from experience.
Agent Memory is available now on EverOS. To get started: everos.evermind.ai
Open-source repository: github.com/EverMind-AI/EverOS
You may also like these
Related

Skill Hub: a measured foundation for community-powered agents
skillhub,skill benchmark,SKILL.md,community skills,ai agent

Introducing mRAG: How EverOS Retrieves What Actually Matters
mRAG, multimodal, multimodal retrieval, RAG

Breaking the 100M Token Limit: MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
long term memory, RAG, context, ai agent, OpenClaw, sparse attention, transformers, LLM, KV cache

EverOS: SOTA Results Across Four Memory Benchmarks and What It Means for LLM Agents
EverOS, long term memory, RAG, context, LoCoMo, LongMemEval, PersonaMem
Introducing Self-Evolving Agent Memory: How EverOS Helps Your AI Agents Learn from Experience
This post explains what Agent Memory is, how it works, and what it means for building agents that actually improve over time.
EverMind researchers
About 3 minutes to read
© 2026 EverMind Team.
© 2026 EverMind Team.
© 2026 EverMind Team.