Breaking the 100M Token Limit: MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
We present Memory Sparse Attention (MSA): an end-to-end trainable, scalable sparse latent-state memory framework.
EverMind researchers
About 3 minutes to read

Long-term memory is the holy grail of general-purpose AI agents. While human lifetime memory capacity is estimated at 200–300 million tokens, modern LLMs struggle beyond 200K tokens due to quadratic computational complexity and memory exhaustion.
Current workarounds—like RAG (Retrieval-Augmented Generation) or latent state compression—suffer from structural disconnects or catastrophic forgetting. Our recent paper, "Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens" (MSA), introduces a breakthrough architecture that pushes memory capacity to an unprecedented 100 million tokens while maintaining high retrieval precision.
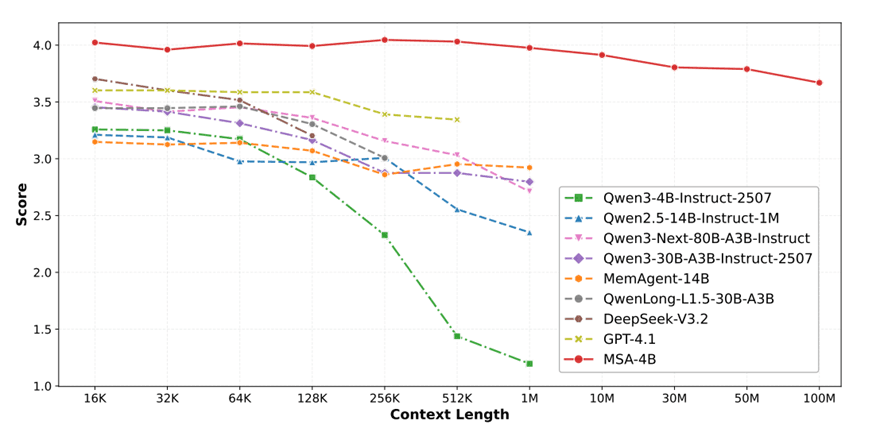
Figure 1: MSA demonstrates unprecedented scalability, maintaining performance with less than 9% degradation across contexts up to 100M tokens.
1. The Core Innovation: Decoupled Memory
MSA achieves linear O(n) complexity by decoupling short-term working memory from long-term memory through a hierarchical storage strategy:
• Router (Routing Keys): Highly compressed feature vectors stored in fast GPU VRAM to decide where to look.
• Memory Content (KV Cache): Full Key-Value tensors stored in large CPU RAM.
Unlike RAG, MSA's routing mechanism is embedded directly inside the Transformer's attention layers. This creates an end-to-end differentiable "native hippocampus"—retrieval and generation are jointly trained, drastically improving multi-hop reasoning.
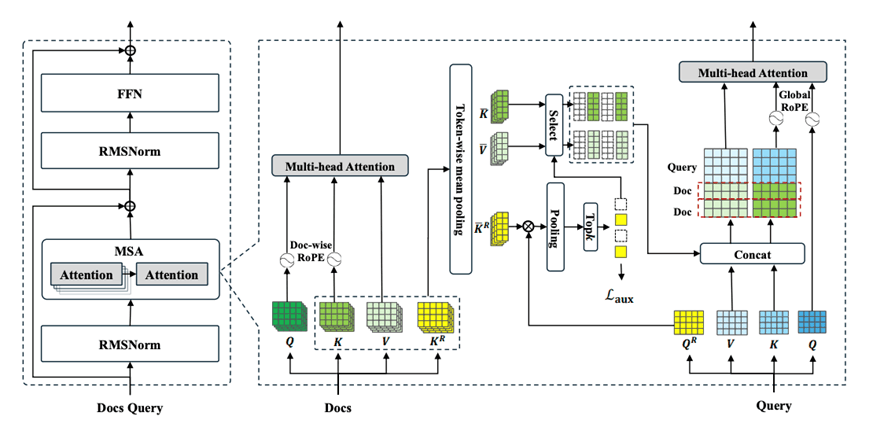
Figure 2: Memory Sparse Attention layer architecture showing the Router K projector and Top-k selection.
2. Overcoming the Extrapolation Barrier
Scaling context length typically breaks standard Rotary Position Embeddings (RoPE). MSA solves this with Document-Level RoPE: the position counter simply resets to zero at the start of each new document. This allows models trained on short texts (e.g., 4K tokens) to seamlessly extrapolate to massive document banks during inference.
Memory Interleave: Iterative Multi-Hop Reasoning
MSA handles complex questions that require chaining evidence across multiple documents. The key points covered:
Standard RAG does a single-shot retrieval; Memory Interleave runs an iterative loop — the model alternates between generating document IDs and reading retrieved content, repeating until it has enough evidence to answer.
The number of documents retrieved per round is dynamically determined by the model, not fixed by a hyperparameter.
Ablation results confirm its importance: removing Memory Interleave causes a 5.3% average drop across QA benchmarks, and 19.2% on HotpotQA (a multi-hop dataset).
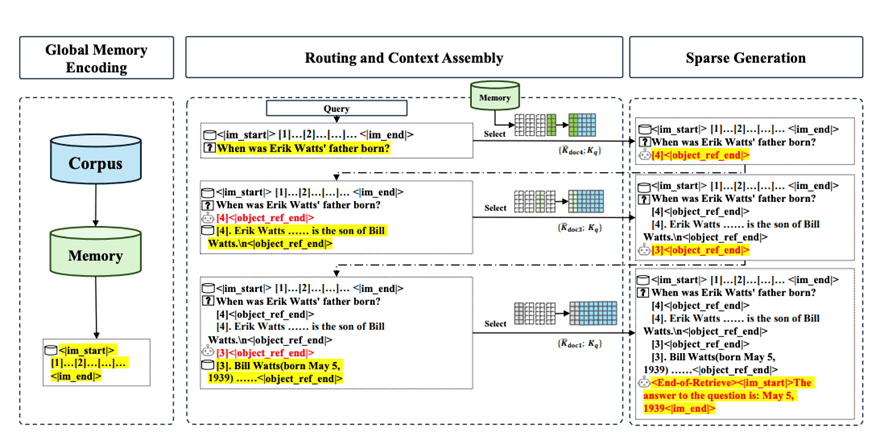
Figure 3: The Three-stage Inference Diagram
3. Experimental Results
In the rigorous Needle-In-A-Haystack (NIAH) benchmark, MSA exhibits exceptional stability. At 1 million tokens, while baseline models collapse to below 25% accuracy, MSA drops by less than 4%.
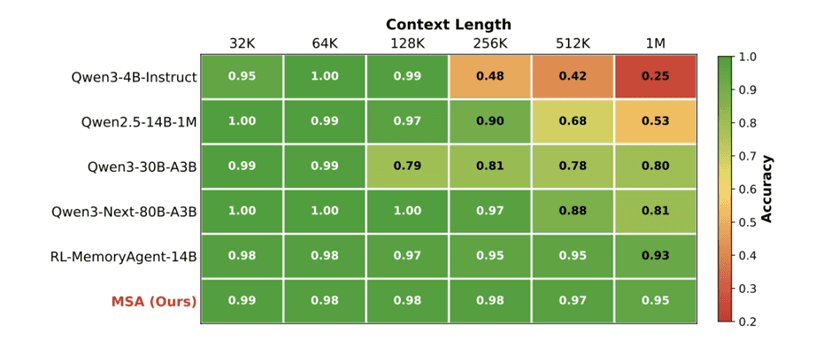
Figure 4: Results on the NIAH evaluation. MSA retains >94% accuracy at 1M tokens.
4. Why This Matters
MSA demonstrates that a 4B-parameter model with the right memory architecture can outperform systems with 60× more parameters. The combination of end-to-end differentiability, hardware-aware tiered storage, document-level positional encoding, and iterative multi-hop reasoning addresses the four core limitations that have historically prevented LLMs from
operating at human-scale memory contexts. As agent-based applications increasingly demand persistent, accurate recall across months or years of interaction history, techniques like MSA will become foundational infrastructure — not research curiosities. At EverMind, we are closely tracking this line of research as part of our mission to build long-term memory infrastructure for AI agents, moving towards AI's Self-Evolving capability.
To explore:
Long-term memory is the holy grail of general-purpose AI agents. While human lifetime memory capacity is estimated at 200–300 million tokens, modern LLMs struggle beyond 200K tokens due to quadratic computational complexity and memory exhaustion.
Current workarounds—like RAG (Retrieval-Augmented Generation) or latent state compression—suffer from structural disconnects or catastrophic forgetting. Our recent paper, "Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens" (MSA), introduces a breakthrough architecture that pushes memory capacity to an unprecedented 100 million tokens while maintaining high retrieval precision.
Figure 1: MSA demonstrates unprecedented scalability, maintaining performance with less than 9% degradation across contexts up to 100M tokens.
1. The Core Innovation: Decoupled Memory
MSA achieves linear O(n) complexity by decoupling short-term working memory from long-term memory through a hierarchical storage strategy:
• Router (Routing Keys): Highly compressed feature vectors stored in fast GPU VRAM to decide where to look.
• Memory Content (KV Cache): Full Key-Value tensors stored in large CPU RAM.
Unlike RAG, MSA's routing mechanism is embedded directly inside the Transformer's attention layers. This creates an end-to-end differentiable "native hippocampus"—retrieval and generation are jointly trained, drastically improving multi-hop reasoning.
Figure 2: Memory Sparse Attention layer architecture showing the Router K projector and Top-k selection.
2. Overcoming the Extrapolation Barrier
Scaling context length typically breaks standard Rotary Position Embeddings (RoPE). MSA solves this with Document-Level RoPE: the position counter simply resets to zero at the start of each new document. This allows models trained on short texts (e.g., 4K tokens) to seamlessly extrapolate to massive document banks during inference.
Memory Interleave: Iterative Multi-Hop Reasoning
MSA handles complex questions that require chaining evidence across multiple documents. The key points covered:
Standard RAG does a single-shot retrieval; Memory Interleave runs an iterative loop — the model alternates between generating document IDs and reading retrieved content, repeating until it has enough evidence to answer.
The number of documents retrieved per round is dynamically determined by the model, not fixed by a hyperparameter.
Ablation results confirm its importance: removing Memory Interleave causes a 5.3% average drop across QA benchmarks, and 19.2% on HotpotQA (a multi-hop dataset).
Figure 3: The Three-stage Inference Diagram
3. Experimental Results
In the rigorous Needle-In-A-Haystack (NIAH) benchmark, MSA exhibits exceptional stability. At 1 million tokens, while baseline models collapse to below 25% accuracy, MSA drops by less than 4%.
Figure 4: Results on the NIAH evaluation. MSA retains >94% accuracy at 1M tokens.
4. Why This Matters
MSA demonstrates that a 4B-parameter model with the right memory architecture can outperform systems with 60× more parameters. The combination of end-to-end differentiability, hardware-aware tiered storage, document-level positional encoding, and iterative multi-hop reasoning addresses the four core limitations that have historically prevented LLMs from
operating at human-scale memory contexts. As agent-based applications increasingly demand persistent, accurate recall across months or years of interaction history, techniques like MSA will become foundational infrastructure — not research curiosities. At EverMind, we are closely tracking this line of research as part of our mission to build long-term memory infrastructure for AI agents, moving towards AI's Self-Evolving capability.
To explore:
You may also like these
Related

Introducing mRAG: How EverOS Retrieves What Actually Matters
mRAG, multimodal, multimodal retrieval, RAG

Introducing Self-Evolving Agent Memory: How EverOS Helps Your AI Agents Learn from Experience
Self-Evolving Agent Memory, Agent Memory, Self-Evolving, Agent Skills, Agent Cases

EverOS: SOTA Results Across Four Memory Benchmarks and What It Means for LLM Agents
EverOS, long term memory, RAG, context, LoCoMo, LongMemEval, PersonaMem

A Unified Evaluation Framework for AI Memory Systems
AI Memory, Evaluation Framework, EverOS, Mem0, MemU, ZEP, MemOS, LoCoMo, LongMemEval
Breaking the 100M Token Limit: MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
We present Memory Sparse Attention (MSA): an end-to-end trainable, scalable sparse latent-state memory framework.
EverMind researchers
About 3 minutes to read

© 2026 EverMind Team.
© 2026 EverMind Team.
© 2026 EverMind Team.