介绍自我进化的智能体记忆:EverOS 如何帮助您的 AI 智能体从经验中学习
介绍自我进化的智能体记忆:EverOS 如何帮助您的 AI 智能体从经验中学习
这篇文章解释了什么是 Agent Memory、它如何运作,以及这对构建真正能随着时间推移不断改进的智能体意味着什么。
EverMind研究人员
大约需要 3 分钟阅读

大多数 AI 智能体都困在一个循环里。它们完成一项任务,然后就忘记了自己是如何完成的。下次再遇到同样的问题时,它们又从头开始——相同的推理过程、相同的试错、相同的错误。它们永远不会变得更好。
EverOS Agent Memory 改变了这一点。它为你的智能体提供了一种结构化的方式,用来记录它们做了什么、学习哪些方法有效,并在下次出现类似任务时建立在这些知识之上。
这篇文章将解释什么是 Agent Memory、它如何运作,以及它对构建真正能随着时间推移不断改进的智能体意味着什么。
User Memory 与 Agent Memory 的区别
EverOS 已经能够从对话中构建持久记忆——跟踪用户说了什么、偏好什么,以及随着时间推移他们是谁。这就是 User Memory:它的目的是让智能体更个性化、更具上下文感知能力。
Agent Memory 是完全不同的东西。它的目的不是更好地理解用户,而是让智能体本身更聪明。
当智能体完成一项任务——研究选项、编写代码、解决多步骤问题——它完成这件事的轨迹本身就包含了有价值的信息。哪些工具调用有效,哪些方法失败了,复杂问题是如何被拆解的,最终结果是什么。这些信息正是未来的智能体在处理类似任务时可以用来更快、更可靠地应对的内容。
Agent Memory 会捕获这些信息,将其结构化,并让它可检索。一个已经处理过数百个任务的智能体,在第 101 个任务上不会从零开始;它会借助积累的经验。
记录了什么
当你将智能体轨迹发送到 EverOS——包括完整的推理步骤序列、工具调用、工具响应和最终答案——系统会将它们处理为两类结构化记忆。
智能体案例
智能体案例是一条特定任务执行的记录。它会捕获:
任务意图——智能体实际想要完成什么,以一个清晰、自包含的陈述来表达。当未来的智能体面对类似问题时,它会用这个作为检索键。
方法——对智能体如何解决问题的压缩记录。方法会按子问题组织:每一步尝试了什么、使用了什么工具或采用了什么推理,以及得到了什么结果。如果某次尝试失败并需要修正,也会记录下来。方法最后会以一个 Outcome 结束,用来总结最终结果。
质量分数——从 0 到 1 的自评得分,反映智能体完成任务的效果有多好。
下面是一个真实的智能体案例,来自一个实现了速率限制中间件的编码智能体:
Task intent: Implement rate limiting middleware for a FastAPI API with default 100 requests per minute per IP, with per-endpoint overrides for /api/auth/login and unlimited /api/health.
Approach:
1. Read existing middleware setup
- Tried: read_file on src/middleware/__init__
智能体技能
智能体案例记录的是具体执行。智能体技能则是在这些案例被整合之后浮现出来的东西。
随着案例围绕某个反复出现的主题不断累积——多个智能体解决数据库比较问题、多个会话实现 API 验证——EverOS 会将它们聚类,并提炼出共享模式形成一项技能。技能是一种可泛化、可复用的最佳实践流程:何时适用、应遵循哪些步骤,以及根据之前失败的尝试应避免哪些陷阱。
一个由搜索智能体案例生成、用于解决框架比较任务的技能可能如下所示:
Skill: Compare Software Tools by Suitability and Performance When to use: When evaluating databases, frameworks, or libraries for specific use cases based on suitability, performance benchmarks, and metrics. Steps: 1. Search for top candidates using web_search with query '[use case] best [tool type] [key requirement] [year] comparison'. 2. Search for performance benchmarks with '[top candidates] benchmark [key metrics] [year]
技能并不锁定于某一个智能体或会话。同一个命名空间中的任何智能体都可以检索并应用它们。一个智能体学到的东西,未来的每个智能体都可以受益。
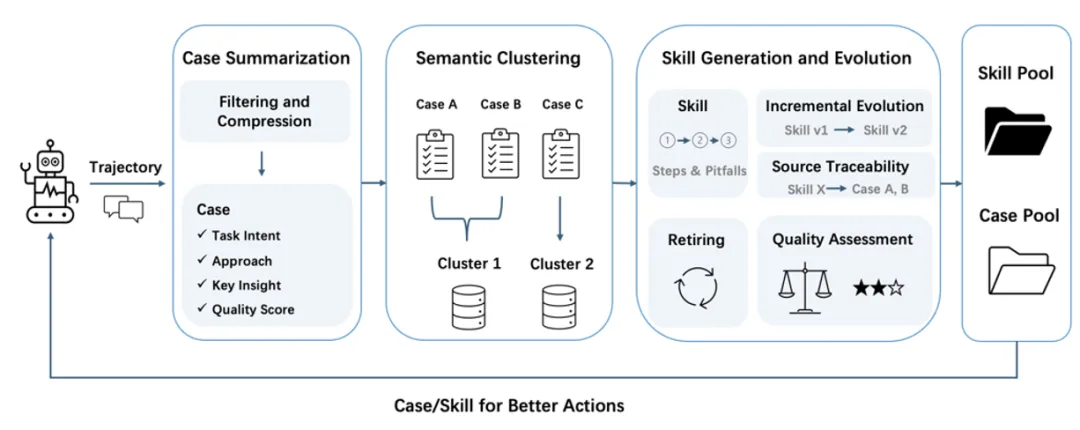
智能体轨迹如何被处理
智能体的原始输出——长串的用户消息、助手推理、工具调用和工具响应——不会被直接存储。长轨迹会在提取前先被压缩。
对于非常长的轨迹,EverOS 会采用一种预压缩策略,将启发式规则与基于 LLM 的压缩结合起来,以减少噪声并改善长上下文处理。该机制旨在帮助 EverOS 高效处理延长的轨迹,同时保留整体连贯性。
压缩完成后,系统会评估这条轨迹是否值得作为案例存储。闲聊、简单问答以及非任务型交互都会被过滤掉。只有以目标为导向的智能体工作——也就是智能体确实在 চেষ্টা完成某件事——才会被提炼成一个案例。
当某个主题簇中积累了足够多的案例后,就会触发技能生成。系统在生成新技能之前会先考虑所有已有技能——通过合并相似模式,而不是创建冗余变体。技能在变得可检索之前还会经过验证,以确保只有足够成熟、可靠的知识会展示给未来的智能体。
智能体如何使用它们的记忆
当未来的智能体接手一项任务时,它可以在开始之前先搜索 Agent Memory 命名空间。搜索会使用任务意图作为查询,返回:
相似的智能体案例——展示过去的智能体如何处理类似问题,包括它们采取了哪些子步骤以及取得了什么结果
相关技能——直接提供可泛化、可应用于当前任务的最佳实践流程
这意味着,一个在构建 Docker 部署指南的智能体,不需要从零开始推导方法。它会检索之前做过这件事的智能体留下的模式:搜索官方文档、识别必要组件、综合成一个可执行示例、加入生产环境建议。推理已经在那里了。
一个评估数据库的搜索智能体,不会重新学习哪些来源可靠,也不会重新学习如何组织比较。一个实现中间件的编码智能体,不会在写新文件之前再去重新发现如何读取现有代码结构。它们依靠的是所有先前智能体积累下来的经验。
适用于各种智能体类型
Agent Memory 并不针对任何特定类型的智能体。在跨三种不同智能体架构的演示中,同一套记忆系统在每种场景下都生成了有用的案例和技能:
一个进行网络研究的搜索智能体产生了捕获比较与推荐工作流的案例,以及用于结构化工具选择和 Docker 部署指导的技能。
一个进行实现工作的编码智能体产生了捕获完整“读代码、实现、测试、迭代”循环的案例,以及用于 Pydantic 验证模式和中间件设计的技能。
一个处理个性化的聊天智能体产生了捕获推荐迭代优化方法的案例,以及用于构建基于类别建议的技能。
智能体类型会变化。记忆结构以及从中学习的机制保持不变。
多智能体系统与共享记忆
单个智能体会积累经验。 由于每条轨迹都独立存储, 多个共享同一记忆命名空间的智能体可以随着时间共同建立起更大的案例和技能池。
在多智能体系统中——例如规划智能体、研究智能体和写作智能体都代表同一个用户协同工作——每个智能体的案例和技能都可以被其他所有智能体搜索到。研究智能体学到的结构化工具使用方式,在规划智能体面对类似的信息收集任务时可能被检索出来。技能可以跨角色泛化。
对于主-从智能体架构,其中一个智能体将任务作为工具调用委派给专门的从属智能体,从属智能体的轨迹都可以分别记录并存储为单独的案例。委派过程中的学习会被保留下来,而不会丢失。
如何使用
使用 agent 端点将你的智能体轨迹发送到 EverOS:
POST /api/v1/memories/agent
{ "user_id": "user_123", "session_id": "session_456", "messages": [ { "role": "user", "content": "Implement rate limiting for the FastAPI app", "timestamp": 1740000000000 }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "call_001", "function": { "name": "read_file", "arguments": "{\"path\": \"src/middleware/__init__.py\"}" } } ], "timestamp": 1740000001000 }, { "role": "tool", "tool_call_id": "call_001", "content": "MIDDLEWARE_STACK = [CORSMiddleware, LoggingMiddleware]", "timestamp": 1740000002000 } // ... rest of trajectory ] }
轨迹会异步处理。提取完成后,可通过搜索请求检索该智能体案例:
POST /api/v1/memories/search
{ "query": "implement rate limiting FastAPI middleware", "memory_types": ["agent_memory"], "filters": { "user_id": "user_123" } }
响应会在 agent_memory 字段下同时包含案例和技能。
这对智能体如何发展意味着什么
提升 AI 智能体的标准做法是重新训练它、微调它,或者写更好的提示词。这些方法都很有价值,但它们改变的都是智能体本身——而且成本高、速度慢,也不一定针对你的智能体在生产环境中真正执行的任务。
Agent Memory 是另一种杠杆。它不改变模型本身,而是让模型能够访问不断增长的、结构化的、面向任务的经验库,而且你的智能体运行得越多,这些经验就越丰富。智能体第一次解决问题时,是靠自己摸索出来的;第十次,就已经有相应的技能可用了。
使用自身积累经验的智能体会更快、更可靠,也更一致。它们不会重复已知的错误,不会重新推导那些已经建立好的模式。它们是在不断叠加,而不是循环打转。
这才是真正意义上的智能体从经验中学习。
Agent Memory 现已在 EverOS 上可用。开始使用: everos.evermind.ai
大多数 AI 智能体都困在一个循环里。它们完成一项任务,然后就忘记了自己是如何完成的。下次再遇到同样的问题时,它们又从头开始——相同的推理过程、相同的试错、相同的错误。它们永远不会变得更好。
EverOS Agent Memory 改变了这一点。它为你的智能体提供了一种结构化的方式,用来记录它们做了什么、学习哪些方法有效,并在下次出现类似任务时建立在这些知识之上。
这篇文章将解释什么是 Agent Memory、它如何运作,以及它对构建真正能随着时间推移不断改进的智能体意味着什么。
User Memory 与 Agent Memory 的区别
EverOS 已经能够从对话中构建持久记忆——跟踪用户说了什么、偏好什么,以及随着时间推移他们是谁。这就是 User Memory:它的目的是让智能体更个性化、更具上下文感知能力。
Agent Memory 是完全不同的东西。它的目的不是更好地理解用户,而是让智能体本身更聪明。
当智能体完成一项任务——研究选项、编写代码、解决多步骤问题——它完成这件事的轨迹本身就包含了有价值的信息。哪些工具调用有效,哪些方法失败了,复杂问题是如何被拆解的,最终结果是什么。这些信息正是未来的智能体在处理类似任务时可以用来更快、更可靠地应对的内容。
Agent Memory 会捕获这些信息,将其结构化,并让它可检索。一个已经处理过数百个任务的智能体,在第 101 个任务上不会从零开始;它会借助积累的经验。
记录了什么
当你将智能体轨迹发送到 EverOS——包括完整的推理步骤序列、工具调用、工具响应和最终答案——系统会将它们处理为两类结构化记忆。
智能体案例
智能体案例是一条特定任务执行的记录。它会捕获:
任务意图——智能体实际想要完成什么,以一个清晰、自包含的陈述来表达。当未来的智能体面对类似问题时,它会用这个作为检索键。
方法——对智能体如何解决问题的压缩记录。方法会按子问题组织:每一步尝试了什么、使用了什么工具或采用了什么推理,以及得到了什么结果。如果某次尝试失败并需要修正,也会记录下来。方法最后会以一个 Outcome 结束,用来总结最终结果。
质量分数——从 0 到 1 的自评得分,反映智能体完成任务的效果有多好。
下面是一个真实的智能体案例,来自一个实现了速率限制中间件的编码智能体:
Task intent: Implement rate limiting middleware for a FastAPI API with default 100 requests per minute per IP, with per-endpoint overrides for /api/auth/login and unlimited /api/health.
Approach:
1. Read existing middleware setup
- Tried: read_file on src/middleware/__init__
智能体技能
智能体案例记录的是具体执行。智能体技能则是在这些案例被整合之后浮现出来的东西。
随着案例围绕某个反复出现的主题不断累积——多个智能体解决数据库比较问题、多个会话实现 API 验证——EverOS 会将它们聚类,并提炼出共享模式形成一项技能。技能是一种可泛化、可复用的最佳实践流程:何时适用、应遵循哪些步骤,以及根据之前失败的尝试应避免哪些陷阱。
一个由搜索智能体案例生成、用于解决框架比较任务的技能可能如下所示:
Skill: Compare Software Tools by Suitability and Performance When to use: When evaluating databases, frameworks, or libraries for specific use cases based on suitability, performance benchmarks, and metrics. Steps: 1. Search for top candidates using web_search with query '[use case] best [tool type] [key requirement] [year] comparison'. 2. Search for performance benchmarks with '[top candidates] benchmark [key metrics] [year]
技能并不锁定于某一个智能体或会话。同一个命名空间中的任何智能体都可以检索并应用它们。一个智能体学到的东西,未来的每个智能体都可以受益。
智能体轨迹如何被处理
智能体的原始输出——长串的用户消息、助手推理、工具调用和工具响应——不会被直接存储。长轨迹会在提取前先被压缩。
对于非常长的轨迹,EverOS 会采用一种预压缩策略,将启发式规则与基于 LLM 的压缩结合起来,以减少噪声并改善长上下文处理。该机制旨在帮助 EverOS 高效处理延长的轨迹,同时保留整体连贯性。
压缩完成后,系统会评估这条轨迹是否值得作为案例存储。闲聊、简单问答以及非任务型交互都会被过滤掉。只有以目标为导向的智能体工作——也就是智能体确实在 চেষ্টা完成某件事——才会被提炼成一个案例。
当某个主题簇中积累了足够多的案例后,就会触发技能生成。系统在生成新技能之前会先考虑所有已有技能——通过合并相似模式,而不是创建冗余变体。技能在变得可检索之前还会经过验证,以确保只有足够成熟、可靠的知识会展示给未来的智能体。
智能体如何使用它们的记忆
当未来的智能体接手一项任务时,它可以在开始之前先搜索 Agent Memory 命名空间。搜索会使用任务意图作为查询,返回:
相似的智能体案例——展示过去的智能体如何处理类似问题,包括它们采取了哪些子步骤以及取得了什么结果
相关技能——直接提供可泛化、可应用于当前任务的最佳实践流程
这意味着,一个在构建 Docker 部署指南的智能体,不需要从零开始推导方法。它会检索之前做过这件事的智能体留下的模式:搜索官方文档、识别必要组件、综合成一个可执行示例、加入生产环境建议。推理已经在那里了。
一个评估数据库的搜索智能体,不会重新学习哪些来源可靠,也不会重新学习如何组织比较。一个实现中间件的编码智能体,不会在写新文件之前再去重新发现如何读取现有代码结构。它们依靠的是所有先前智能体积累下来的经验。
适用于各种智能体类型
Agent Memory 并不针对任何特定类型的智能体。在跨三种不同智能体架构的演示中,同一套记忆系统在每种场景下都生成了有用的案例和技能:
一个进行网络研究的搜索智能体产生了捕获比较与推荐工作流的案例,以及用于结构化工具选择和 Docker 部署指导的技能。
一个进行实现工作的编码智能体产生了捕获完整“读代码、实现、测试、迭代”循环的案例,以及用于 Pydantic 验证模式和中间件设计的技能。
一个处理个性化的聊天智能体产生了捕获推荐迭代优化方法的案例,以及用于构建基于类别建议的技能。
智能体类型会变化。记忆结构以及从中学习的机制保持不变。
多智能体系统与共享记忆
单个智能体会积累经验。 由于每条轨迹都独立存储, 多个共享同一记忆命名空间的智能体可以随着时间共同建立起更大的案例和技能池。
在多智能体系统中——例如规划智能体、研究智能体和写作智能体都代表同一个用户协同工作——每个智能体的案例和技能都可以被其他所有智能体搜索到。研究智能体学到的结构化工具使用方式,在规划智能体面对类似的信息收集任务时可能被检索出来。技能可以跨角色泛化。
对于主-从智能体架构,其中一个智能体将任务作为工具调用委派给专门的从属智能体,从属智能体的轨迹都可以分别记录并存储为单独的案例。委派过程中的学习会被保留下来,而不会丢失。
如何使用
使用 agent 端点将你的智能体轨迹发送到 EverOS:
POST /api/v1/memories/agent
{ "user_id": "user_123", "session_id": "session_456", "messages": [ { "role": "user", "content": "Implement rate limiting for the FastAPI app", "timestamp": 1740000000000 }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "call_001", "function": { "name": "read_file", "arguments": "{\"path\": \"src/middleware/__init__.py\"}" } } ], "timestamp": 1740000001000 }, { "role": "tool", "tool_call_id": "call_001", "content": "MIDDLEWARE_STACK = [CORSMiddleware, LoggingMiddleware]", "timestamp": 1740000002000 } // ... rest of trajectory ] }
轨迹会异步处理。提取完成后,可通过搜索请求检索该智能体案例:
POST /api/v1/memories/search
{ "query": "implement rate limiting FastAPI middleware", "memory_types": ["agent_memory"], "filters": { "user_id": "user_123" } }
响应会在 agent_memory 字段下同时包含案例和技能。
这对智能体如何发展意味着什么
提升 AI 智能体的标准做法是重新训练它、微调它,或者写更好的提示词。这些方法都很有价值,但它们改变的都是智能体本身——而且成本高、速度慢,也不一定针对你的智能体在生产环境中真正执行的任务。
Agent Memory 是另一种杠杆。它不改变模型本身,而是让模型能够访问不断增长的、结构化的、面向任务的经验库,而且你的智能体运行得越多,这些经验就越丰富。智能体第一次解决问题时,是靠自己摸索出来的;第十次,就已经有相应的技能可用了。
使用自身积累经验的智能体会更快、更可靠,也更一致。它们不会重复已知的错误,不会重新推导那些已经建立好的模式。它们是在不断叠加,而不是循环打转。
这才是真正意义上的智能体从经验中学习。
Agent Memory 现已在 EverOS 上可用。开始使用: everos.evermind.ai
大多数 AI 智能体都困在一个循环里。它们完成一项任务,然后就忘记了自己是如何完成的。下次再遇到同样的问题时,它们又从头开始——相同的推理过程、相同的试错、相同的错误。它们永远不会变得更好。
EverOS Agent Memory 改变了这一点。它为你的智能体提供了一种结构化的方式,用来记录它们做了什么、学习哪些方法有效,并在下次出现类似任务时建立在这些知识之上。
这篇文章将解释什么是 Agent Memory、它如何运作,以及它对构建真正能随着时间推移不断改进的智能体意味着什么。
User Memory 与 Agent Memory 的区别
EverOS 已经能够从对话中构建持久记忆——跟踪用户说了什么、偏好什么,以及随着时间推移他们是谁。这就是 User Memory:它的目的是让智能体更个性化、更具上下文感知能力。
Agent Memory 是完全不同的东西。它的目的不是更好地理解用户,而是让智能体本身更聪明。
当智能体完成一项任务——研究选项、编写代码、解决多步骤问题——它完成这件事的轨迹本身就包含了有价值的信息。哪些工具调用有效,哪些方法失败了,复杂问题是如何被拆解的,最终结果是什么。这些信息正是未来的智能体在处理类似任务时可以用来更快、更可靠地应对的内容。
Agent Memory 会捕获这些信息,将其结构化,并让它可检索。一个已经处理过数百个任务的智能体,在第 101 个任务上不会从零开始;它会借助积累的经验。
记录了什么
当你将智能体轨迹发送到 EverOS——包括完整的推理步骤序列、工具调用、工具响应和最终答案——系统会将它们处理为两类结构化记忆。
智能体案例
智能体案例是一条特定任务执行的记录。它会捕获:
任务意图——智能体实际想要完成什么,以一个清晰、自包含的陈述来表达。当未来的智能体面对类似问题时,它会用这个作为检索键。
方法——对智能体如何解决问题的压缩记录。方法会按子问题组织:每一步尝试了什么、使用了什么工具或采用了什么推理,以及得到了什么结果。如果某次尝试失败并需要修正,也会记录下来。方法最后会以一个 Outcome 结束,用来总结最终结果。
质量分数——从 0 到 1 的自评得分,反映智能体完成任务的效果有多好。
下面是一个真实的智能体案例,来自一个实现了速率限制中间件的编码智能体:
Task intent: Implement rate limiting middleware for a FastAPI API with default 100 requests per minute per IP, with per-endpoint overrides for /api/auth/login and unlimited /api/health.
Approach:
1. Read existing middleware setup
- Tried: read_file on src/middleware/__init__
智能体技能
智能体案例记录的是具体执行。智能体技能则是在这些案例被整合之后浮现出来的东西。
随着案例围绕某个反复出现的主题不断累积——多个智能体解决数据库比较问题、多个会话实现 API 验证——EverOS 会将它们聚类,并提炼出共享模式形成一项技能。技能是一种可泛化、可复用的最佳实践流程:何时适用、应遵循哪些步骤,以及根据之前失败的尝试应避免哪些陷阱。
一个由搜索智能体案例生成、用于解决框架比较任务的技能可能如下所示:
Skill: Compare Software Tools by Suitability and Performance When to use: When evaluating databases, frameworks, or libraries for specific use cases based on suitability, performance benchmarks, and metrics. Steps: 1. Search for top candidates using web_search with query '[use case] best [tool type] [key requirement] [year] comparison'. 2. Search for performance benchmarks with '[top candidates] benchmark [key metrics] [year]
技能并不锁定于某一个智能体或会话。同一个命名空间中的任何智能体都可以检索并应用它们。一个智能体学到的东西,未来的每个智能体都可以受益。
智能体轨迹如何被处理
智能体的原始输出——长串的用户消息、助手推理、工具调用和工具响应——不会被直接存储。长轨迹会在提取前先被压缩。
对于非常长的轨迹,EverOS 会采用一种预压缩策略,将启发式规则与基于 LLM 的压缩结合起来,以减少噪声并改善长上下文处理。该机制旨在帮助 EverOS 高效处理延长的轨迹,同时保留整体连贯性。
压缩完成后,系统会评估这条轨迹是否值得作为案例存储。闲聊、简单问答以及非任务型交互都会被过滤掉。只有以目标为导向的智能体工作——也就是智能体确实在 চেষ্টা完成某件事——才会被提炼成一个案例。
当某个主题簇中积累了足够多的案例后,就会触发技能生成。系统在生成新技能之前会先考虑所有已有技能——通过合并相似模式,而不是创建冗余变体。技能在变得可检索之前还会经过验证,以确保只有足够成熟、可靠的知识会展示给未来的智能体。
智能体如何使用它们的记忆
当未来的智能体接手一项任务时,它可以在开始之前先搜索 Agent Memory 命名空间。搜索会使用任务意图作为查询,返回:
相似的智能体案例——展示过去的智能体如何处理类似问题,包括它们采取了哪些子步骤以及取得了什么结果
相关技能——直接提供可泛化、可应用于当前任务的最佳实践流程
这意味着,一个在构建 Docker 部署指南的智能体,不需要从零开始推导方法。它会检索之前做过这件事的智能体留下的模式:搜索官方文档、识别必要组件、综合成一个可执行示例、加入生产环境建议。推理已经在那里了。
一个评估数据库的搜索智能体,不会重新学习哪些来源可靠,也不会重新学习如何组织比较。一个实现中间件的编码智能体,不会在写新文件之前再去重新发现如何读取现有代码结构。它们依靠的是所有先前智能体积累下来的经验。
适用于各种智能体类型
Agent Memory 并不针对任何特定类型的智能体。在跨三种不同智能体架构的演示中,同一套记忆系统在每种场景下都生成了有用的案例和技能:
一个进行网络研究的搜索智能体产生了捕获比较与推荐工作流的案例,以及用于结构化工具选择和 Docker 部署指导的技能。
一个进行实现工作的编码智能体产生了捕获完整“读代码、实现、测试、迭代”循环的案例,以及用于 Pydantic 验证模式和中间件设计的技能。
一个处理个性化的聊天智能体产生了捕获推荐迭代优化方法的案例,以及用于构建基于类别建议的技能。
智能体类型会变化。记忆结构以及从中学习的机制保持不变。
多智能体系统与共享记忆
单个智能体会积累经验。 由于每条轨迹都独立存储, 多个共享同一记忆命名空间的智能体可以随着时间共同建立起更大的案例和技能池。
在多智能体系统中——例如规划智能体、研究智能体和写作智能体都代表同一个用户协同工作——每个智能体的案例和技能都可以被其他所有智能体搜索到。研究智能体学到的结构化工具使用方式,在规划智能体面对类似的信息收集任务时可能被检索出来。技能可以跨角色泛化。
对于主-从智能体架构,其中一个智能体将任务作为工具调用委派给专门的从属智能体,从属智能体的轨迹都可以分别记录并存储为单独的案例。委派过程中的学习会被保留下来,而不会丢失。
如何使用
使用 agent 端点将你的智能体轨迹发送到 EverOS:
POST /api/v1/memories/agent
{ "user_id": "user_123", "session_id": "session_456", "messages": [ { "role": "user", "content": "Implement rate limiting for the FastAPI app", "timestamp": 1740000000000 }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "call_001", "function": { "name": "read_file", "arguments": "{\"path\": \"src/middleware/__init__.py\"}" } } ], "timestamp": 1740000001000 }, { "role": "tool", "tool_call_id": "call_001", "content": "MIDDLEWARE_STACK = [CORSMiddleware, LoggingMiddleware]", "timestamp": 1740000002000 } // ... rest of trajectory ] }
轨迹会异步处理。提取完成后,可通过搜索请求检索该智能体案例:
POST /api/v1/memories/search
{ "query": "implement rate limiting FastAPI middleware", "memory_types": ["agent_memory"], "filters": { "user_id": "user_123" } }
响应会在 agent_memory 字段下同时包含案例和技能。
这对智能体如何发展意味着什么
提升 AI 智能体的标准做法是重新训练它、微调它,或者写更好的提示词。这些方法都很有价值,但它们改变的都是智能体本身——而且成本高、速度慢,也不一定针对你的智能体在生产环境中真正执行的任务。
Agent Memory 是另一种杠杆。它不改变模型本身,而是让模型能够访问不断增长的、结构化的、面向任务的经验库,而且你的智能体运行得越多,这些经验就越丰富。智能体第一次解决问题时,是靠自己摸索出来的;第十次,就已经有相应的技能可用了。
使用自身积累经验的智能体会更快、更可靠,也更一致。它们不会重复已知的错误,不会重新推导那些已经建立好的模式。它们是在不断叠加,而不是循环打转。
这才是真正意义上的智能体从经验中学习。
Agent Memory 现已在 EverOS 上可用。开始使用: everos.evermind.ai
您可能还喜欢这些
相关

Skill Hub: a measured foundation for community-powered agents
skillhub,skill benchmark,SKILL.md,community skills,ai agent

介绍 mRAG:EverOS 如何检索真正重要的信息
mRAG,多模态,多模态检索,RAG

突破 1 亿 Token 限制:MSA 架构为 LLM 实现高效端到端长期记忆
长期记忆、RAG、上下文、AI 智能体、OpenClaw、稀疏注意力、Transformer、LLM、KV 缓存

EverOS:四项内存基准测试中的 SOTA 结果及其对 LLM 智能体的意义
EverOS、长期记忆、RAG、上下文、LoCoMo、LongMemEval、PersonaMem
介绍自我进化的智能体记忆:EverOS 如何帮助您的 AI 智能体从经验中学习
这篇文章解释了什么是 Agent Memory、它如何运作,以及这对构建真正能随着时间推移不断改进的智能体意味着什么。
EverMind研究人员
大约需要 3 分钟阅读
