突破 1 亿 Token 限制:MSA 架构为 LLM 实现高效端到端长期记忆
突破 1 亿 Token 限制:MSA 架构为 LLM 实现高效端到端长期记忆
我们提出记忆稀疏注意力(MSA):一种端到端可训练、可扩展的稀疏潜状态记忆框架。
EverMind研究人员
大约需要 3 分钟阅读

长期记忆是通用 AI 智能体的圣杯。尽管人类终身记忆容量估计为 2亿–3亿个 token,但由于二次方计算复杂度和内存耗尽,现代 LLM 在超过 20 万 token 后就难以应对。
当前的替代方案——如 RAG(检索增强生成)或潜状态压缩——存在结构性断裂或灾难性遗忘问题。我们最近的论文《面向高效端到端记忆模型扩展到 1 亿 token 的记忆稀疏注意力》(MSA)提出了一种突破性架构,将记忆容量推至前所未有的 1 亿个 token,同时保持高检索精度。
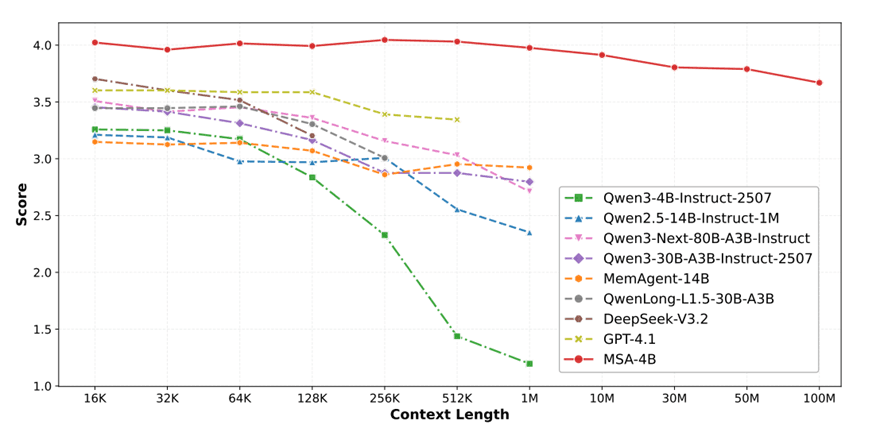
图 1:MSA 展现出前所未有的可扩展性,在最多 1 亿 token 的上下文中性能下降不到 9%,仍能保持稳定表现。
1. 核心创新:解耦记忆
MSA 通过分层存储策略,将短期工作记忆与长期记忆解耦,从而实现线性 O(n) 复杂度:
• 路由器(Routing Keys): 存储在高速 GPU VRAM 中的高压缩特征向量,用于决定去哪里查找。
• 记忆内容(KV Cache): 存储在大容量 CPU RAM 中的完整 Key-Value 张量。
与 RAG 不同,MSA 的路由机制直接嵌入到 Transformer 的注意力层中。这就形成了一个端到端可微分的“原生海马体”——检索与生成联合训练,显著提升多跳推理能力。
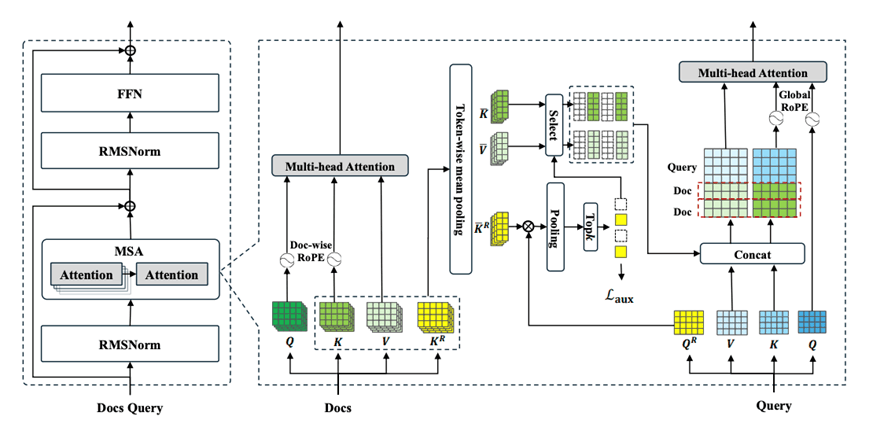
图 2:Memory Sparse Attention 层架构,展示了 Router K 投影器和 Top-k 选择。
2. 克服外推瓶颈
扩展上下文长度通常会破坏标准的旋转位置嵌入(RoPE)。MSA 通过文档级 RoPE 解决了这一问题:位置计数器在每个新文档开始时简单地重置为零。这使得在短文本(如 4K token)上训练的模型在推理时可以无缝外推到庞大的文档库。
记忆交错:迭代式多跳推理
MSA 处理需要跨多个文档串联证据的复杂问题。要点如下:
标准 RAG 只进行一次性检索;Memory Interleave 运行一个 迭代循环 ——模型在生成文档 ID 与读取检索到的内容之间交替进行,重复直到获得足够证据作答。
每轮检索的文档数量由 模型动态决定 ,而不是由超参数固定。
消融结果证实了其重要性:移除 Memory Interleave 会导致 各项 QA 基准平均下降 5.3% ,在 HotpotQA 上下降 19.2% (多跳数据集)。
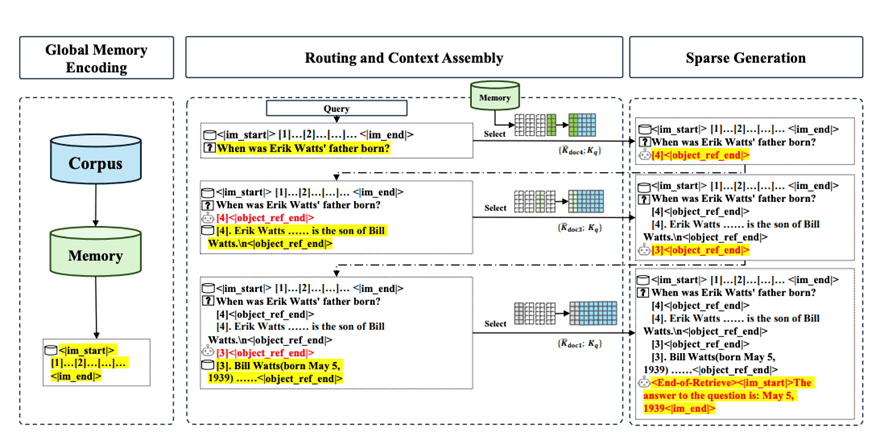
图 3:三阶段推理示意图
3. 实验结果
在严格的 Needle-In-A-Haystack(NIAH,针尖找麦堆)基准中,MSA 表现出极高的稳定性。在 100 万 token 时,基线模型的准确率崩溃到 25% 以下,而 MSA 的下降不到 4%。
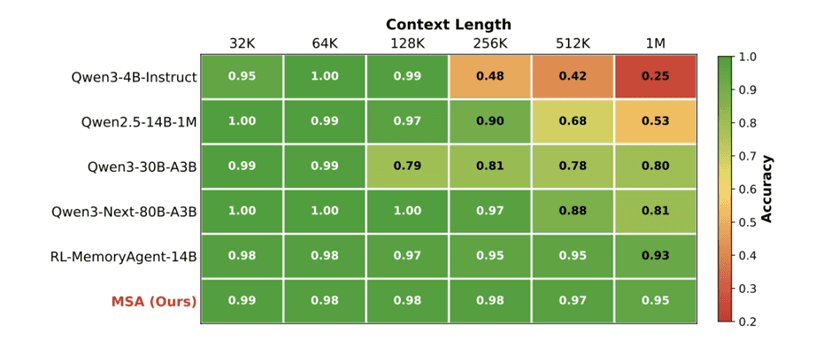
图 4:NIAH 评测结果。MSA 在 100 万 token 时仍保持 >94% 的准确率。
4. 为什么这很重要
MSA 表明,只要采用合适的记忆架构,4B 参数模型就能胜过参数量多 60 倍的系统。端到端可微分、面向硬件的分层存储、文档级位置编码以及迭代式多跳推理的组合,解决了历史上阻碍 LLM 从
在类人规模记忆上下文中运行的四大核心限制。随着基于智能体的应用越来越需要在数月甚至数年的交互历史中保持持久、准确的回忆,像 MSA 这样的技术将成为基础设施,而不只是研究新奇玩意儿。作为我们为 AI 智能体构建长期记忆基础设施、迈向 AI 自我进化能力这一使命的一部分,EverMind 正密切关注这一研究方向。
了解更多:
长期记忆是通用 AI 智能体的圣杯。尽管人类终身记忆容量估计为 2亿–3亿个 token,但由于二次方计算复杂度和内存耗尽,现代 LLM 在超过 20 万 token 后就难以应对。
当前的替代方案——如 RAG(检索增强生成)或潜状态压缩——存在结构性断裂或灾难性遗忘问题。我们最近的论文《面向高效端到端记忆模型扩展到 1 亿 token 的记忆稀疏注意力》(MSA)提出了一种突破性架构,将记忆容量推至前所未有的 1 亿个 token,同时保持高检索精度。
图 1:MSA 展现出前所未有的可扩展性,在最多 1 亿 token 的上下文中性能下降不到 9%,仍能保持稳定表现。
1. 核心创新:解耦记忆
MSA 通过分层存储策略,将短期工作记忆与长期记忆解耦,从而实现线性 O(n) 复杂度:
• 路由器(Routing Keys): 存储在高速 GPU VRAM 中的高压缩特征向量,用于决定去哪里查找。
• 记忆内容(KV Cache): 存储在大容量 CPU RAM 中的完整 Key-Value 张量。
与 RAG 不同,MSA 的路由机制直接嵌入到 Transformer 的注意力层中。这就形成了一个端到端可微分的“原生海马体”——检索与生成联合训练,显著提升多跳推理能力。
图 2:Memory Sparse Attention 层架构,展示了 Router K 投影器和 Top-k 选择。
2. 克服外推瓶颈
扩展上下文长度通常会破坏标准的旋转位置嵌入(RoPE)。MSA 通过文档级 RoPE 解决了这一问题:位置计数器在每个新文档开始时简单地重置为零。这使得在短文本(如 4K token)上训练的模型在推理时可以无缝外推到庞大的文档库。
记忆交错:迭代式多跳推理
MSA 处理需要跨多个文档串联证据的复杂问题。要点如下:
标准 RAG 只进行一次性检索;Memory Interleave 运行一个 迭代循环 ——模型在生成文档 ID 与读取检索到的内容之间交替进行,重复直到获得足够证据作答。
每轮检索的文档数量由 模型动态决定 ,而不是由超参数固定。
消融结果证实了其重要性:移除 Memory Interleave 会导致 各项 QA 基准平均下降 5.3% ,在 HotpotQA 上下降 19.2% (多跳数据集)。
图 3:三阶段推理示意图
3. 实验结果
在严格的 Needle-In-A-Haystack(NIAH,针尖找麦堆)基准中,MSA 表现出极高的稳定性。在 100 万 token 时,基线模型的准确率崩溃到 25% 以下,而 MSA 的下降不到 4%。
图 4:NIAH 评测结果。MSA 在 100 万 token 时仍保持 >94% 的准确率。
4. 为什么这很重要
MSA 表明,只要采用合适的记忆架构,4B 参数模型就能胜过参数量多 60 倍的系统。端到端可微分、面向硬件的分层存储、文档级位置编码以及迭代式多跳推理的组合,解决了历史上阻碍 LLM 从
在类人规模记忆上下文中运行的四大核心限制。随着基于智能体的应用越来越需要在数月甚至数年的交互历史中保持持久、准确的回忆,像 MSA 这样的技术将成为基础设施,而不只是研究新奇玩意儿。作为我们为 AI 智能体构建长期记忆基础设施、迈向 AI 自我进化能力这一使命的一部分,EverMind 正密切关注这一研究方向。
了解更多:
您可能还喜欢这些
相关

介绍 mRAG:EverOS 如何检索真正重要的信息
mRAG,多模态,多模态检索,RAG

介绍自我进化的智能体记忆:EverOS 如何帮助您的 AI 智能体从经验中学习
自我进化的智能体记忆、智能体记忆、自我进化、智能体技能、智能体案例

EverOS:四项内存基准测试中的 SOTA 结果及其对 LLM 智能体的意义
EverOS、长期记忆、RAG、上下文、LoCoMo、LongMemEval、PersonaMem

人工智能记忆系统统一评估框架
AI 记忆、评估框架、EverOS、Mem0、MemU、ZEP、MemOS、LoCoMo、LongMemEval
突破 1 亿 Token 限制:MSA 架构为 LLM 实现高效端到端长期记忆
我们提出记忆稀疏注意力(MSA):一种端到端可训练、可扩展的稀疏潜状态记忆框架。
EverMind研究人员
大约需要 3 分钟阅读
