人工智能记忆系统统一评估框架
人工智能记忆系统统一评估框架
使用统一、生产级的评估框架,我们在相同的数据集、指标和答案模型下,对领先的记忆系统——EverOS、Mem0、MemOS、Zep 和 MemU——进行了基准测试。该框架为评估智能体时代真实世界的记忆性能提供了一个公平、透明且可复现的标准。而 EverOS 在 LoCoMo 和 LongMemEval 上都交出了同类最佳的结果。
EverMind研究人员
大约需要 3 分钟阅读

可靠、可复现且达到生产级
随着长期记忆成为下一代 AI Agent 的核心能力,以严谨且公平的方式评估记忆系统变得前所未有的重要。为支持透明的基准测试,我们构建了一个统一的评估框架,用于衡量多个具有影响力的记忆系统在真实世界中的表现——包括开源和生产级 API。
评估范围
除 EverOS 外,我们的框架还支持四种广泛使用的记忆系统:
Mem0
MemOS
Zep
MemU
这些系统的选择基于它们的广泛采用、公开基准和全球影响力。由于许多商业产品与其开源版本存在显著差异,我们通过各自的在线 API 端点对所有系统进行评估,以反映真实的生产行为,并确保苹果对苹果的比较。
实现方法
我们的适配器建立在以下基础之上:
官方开源仓库:Mem0、MemOS、Zep
官方文档:Mem0、MemOS、MemU、Zep
统一方法论:相同的流水线、数据集、指标
一致的答案生成:所有系统都使用 GPT-4.1-mini 作为 LLM,从而隔离记忆后端的性能差异
在实现过程中,我们发现并修复了公开参考代码中的若干问题,以确保每个系统都能在最佳状态下被评估:
关键调整
Mem0 时区修正
最新 API 返回的时间戳为 PDT;我们加入了时区标准化,以实现正确的时间推理。
MemU 检索增强
/related-memory-items端点仅检索有限上下文;我们遵循其文档,通过类别摘要增强检索。Zep API 迁移(v2 → v3)
公开评估代码仍在使用 v2;我们已将适配器完整迁移到官方 v3 API。
Zep 时间戳语义
Zep 记录的是事件时间戳,而不是对话时间戳。
示例:“Anna 昨天吃了一个汉堡” → 即使是在 3 月 2 日 讨论,也会被存储为 3 月 1 日。
他们的团队为时间相关问题提供了优化提示词——我们采用这些提示词,以确保按照每个系统的设计意图进行公平使用。
由此可见一个核心原则:每个记忆系统都使用其自身的官方提示策略,而不是强行套用统一模板。
评估结果
LoCoMo 基准
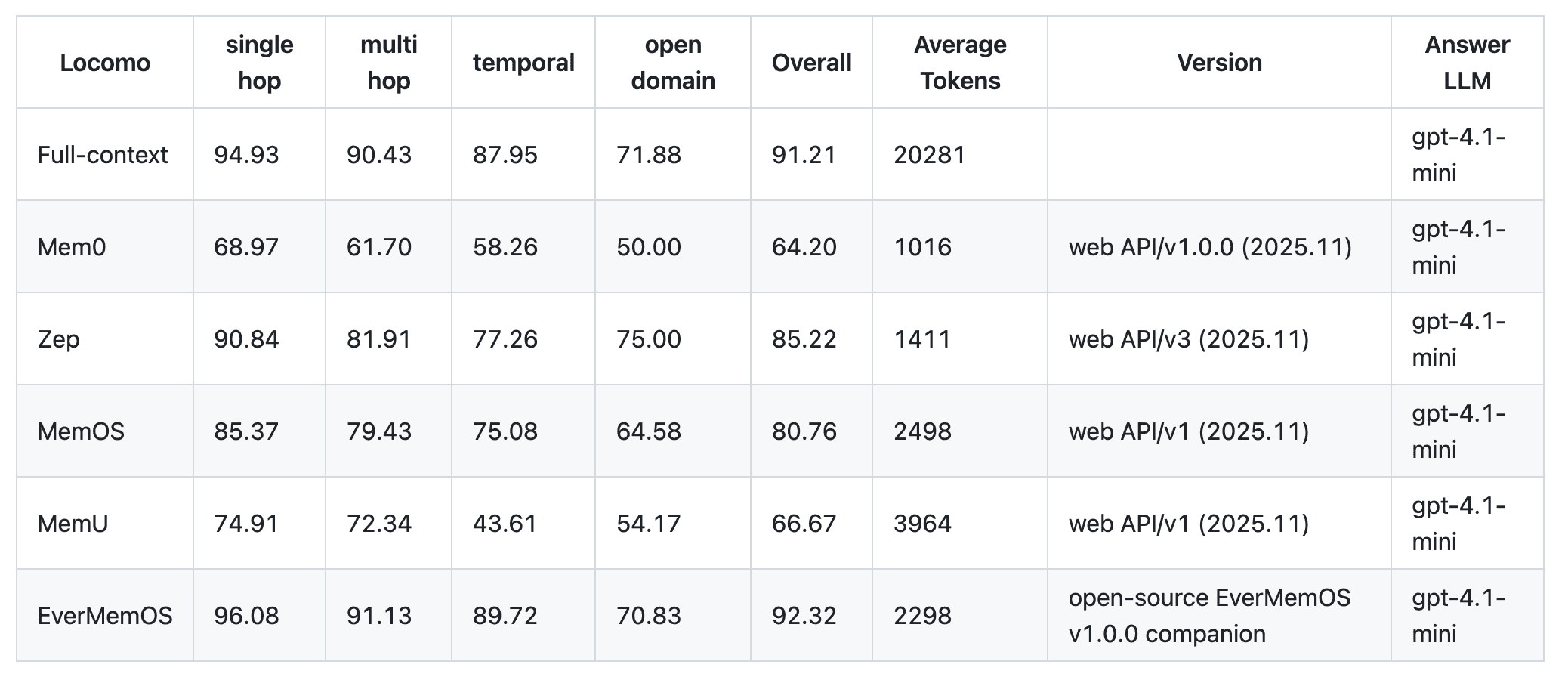
Full-context = 将整个对话输入模型的基线。
LongMemEval

所有中间数据和评估输出均已公开,地址为 EverMind-AI/EverOS_Eval_Results,以实现完全可复现。
框架核心特性
⭐ 统一且模块化的评估框架
一个代码库支持所有系统
即插即用的适配器(EverOS、Mem0、MemOS、MemU、Zep)
开箱即支持多个基准测试
一致的指标、一致的答案 LLM、一致的流水线
⭐ 自动兼容性检测
该框架可自动适配以下情况:
单用户与多用户对话日志
问答格式与多项选择格式
有无时间戳
系统特定的提示词要求
⭐ 稳健的检查点机制
可从任意阶段恢复:摄取 → 搜索 → 回答 → 评分
按对话进行搜索检查点保存
按每 400 个问题进行回答检查点保存
结语
随着长期记忆成为 Agentic AI 的基础,公平且可复现的评估至关重要。借助这一框架,研究人员和开发者可以可靠地对各种记忆系统进行基准测试——从时间推理到多会话连续性——并使用行业标准数据集和生产级 API。
如果你想查看结果或参与贡献,请访问仓库:GitHub
可靠、可复现且达到生产级
随着长期记忆成为下一代 AI Agent 的核心能力,以严谨且公平的方式评估记忆系统变得前所未有的重要。为支持透明的基准测试,我们构建了一个统一的评估框架,用于衡量多个具有影响力的记忆系统在真实世界中的表现——包括开源和生产级 API。
评估范围
除 EverOS 外,我们的框架还支持四种广泛使用的记忆系统:
Mem0
MemOS
Zep
MemU
这些系统的选择基于它们的广泛采用、公开基准和全球影响力。由于许多商业产品与其开源版本存在显著差异,我们通过各自的在线 API 端点对所有系统进行评估,以反映真实的生产行为,并确保苹果对苹果的比较。
实现方法
我们的适配器建立在以下基础之上:
官方开源仓库:Mem0、MemOS、Zep
官方文档:Mem0、MemOS、MemU、Zep
统一方法论:相同的流水线、数据集、指标
一致的答案生成:所有系统都使用 GPT-4.1-mini 作为 LLM,从而隔离记忆后端的性能差异
在实现过程中,我们发现并修复了公开参考代码中的若干问题,以确保每个系统都能在最佳状态下被评估:
关键调整
Mem0 时区修正
最新 API 返回的时间戳为 PDT;我们加入了时区标准化,以实现正确的时间推理。
MemU 检索增强
/related-memory-items端点仅检索有限上下文;我们遵循其文档,通过类别摘要增强检索。Zep API 迁移(v2 → v3)
公开评估代码仍在使用 v2;我们已将适配器完整迁移到官方 v3 API。
Zep 时间戳语义
Zep 记录的是事件时间戳,而不是对话时间戳。
示例:“Anna 昨天吃了一个汉堡” → 即使是在 3 月 2 日 讨论,也会被存储为 3 月 1 日。
他们的团队为时间相关问题提供了优化提示词——我们采用这些提示词,以确保按照每个系统的设计意图进行公平使用。
由此可见一个核心原则:每个记忆系统都使用其自身的官方提示策略,而不是强行套用统一模板。
评估结果
LoCoMo 基准
Full-context = 将整个对话输入模型的基线。
LongMemEval
所有中间数据和评估输出均已公开,地址为 EverMind-AI/EverOS_Eval_Results,以实现完全可复现。
框架核心特性
⭐ 统一且模块化的评估框架
一个代码库支持所有系统
即插即用的适配器(EverOS、Mem0、MemOS、MemU、Zep)
开箱即支持多个基准测试
一致的指标、一致的答案 LLM、一致的流水线
⭐ 自动兼容性检测
该框架可自动适配以下情况:
单用户与多用户对话日志
问答格式与多项选择格式
有无时间戳
系统特定的提示词要求
⭐ 稳健的检查点机制
可从任意阶段恢复:摄取 → 搜索 → 回答 → 评分
按对话进行搜索检查点保存
按每 400 个问题进行回答检查点保存
结语
随着长期记忆成为 Agentic AI 的基础,公平且可复现的评估至关重要。借助这一框架,研究人员和开发者可以可靠地对各种记忆系统进行基准测试——从时间推理到多会话连续性——并使用行业标准数据集和生产级 API。
如果你想查看结果或参与贡献,请访问仓库:GitHub
您可能还喜欢这些
相关

Skill Hub: a measured foundation for community-powered agents
skillhub,skill benchmark,SKILL.md,community skills,ai agent

介绍 mRAG:EverOS 如何检索真正重要的信息
mRAG,多模态,多模态检索,RAG

介绍自我进化的智能体记忆:EverOS 如何帮助您的 AI 智能体从经验中学习
自我进化的智能体记忆、智能体记忆、自我进化、智能体技能、智能体案例

突破 1 亿 Token 限制:MSA 架构为 LLM 实现高效端到端长期记忆
长期记忆、RAG、上下文、AI 智能体、OpenClaw、稀疏注意力、Transformer、LLM、KV 缓存
人工智能记忆系统统一评估框架
使用统一、生产级的评估框架,我们在相同的数据集、指标和答案模型下,对领先的记忆系统——EverOS、Mem0、MemOS、Zep 和 MemU——进行了基准测试。该框架为评估智能体时代真实世界的记忆性能提供了一个公平、透明且可复现的标准。而 EverOS 在 LoCoMo 和 LongMemEval 上都交出了同类最佳的结果。
EverMind研究人员
大约需要 3 分钟阅读
