Skill Hub: a measured foundation for community-powered agents
Skill Hub: a measured foundation for community-powered agents
Skill Hub turns the scattered open SKILL.md ecosystem into a curated, searchable, and benchmarked capability layer for LLM agents — aggregating 800k+ raw skills, releasing 100k audited OSI-compliant skills, and showing statistically significant gains across four real-world benchmarks.
EverMind researchers
About 3 minutes to read

The open SKILL.md ecosystem now numbers in the millions of files. We aggregated it, curated it, learned to match it to real tasks — and then stress-tested whether community skills actually make agents better. Here's what we built, and what the benchmarks showed.
Skill Hub Research · 10 min read · Fully open-source, audited, and 100% OSI-compliant
Large language models are increasingly the engine of agents that plan and execute long-horizon work rather than answer isolated questions. Yet even the strongest frontier models still complete these tasks unreliably — and that gap is hard to close with a bigger base model alone. One of the most promising answers is to externalize capability into modular units that an agent can load at inference time.
Agent skills — SKILL.md files — do exactly this: they package reusable procedural knowledge into units an agent can pull in on demand. A community ecosystem of these skills has formed remarkably fast, with public repositories now accumulating skills by the million. In principle, that's an enormous, open source of capability for any agent.
In practice, abundance hasn't translated into reliability. Community skills are scattered across channels, heavily redundant, wildly uneven in quality, and occasionally carry safety risk. The question that mattered to us was never "how many skills exist?" It was sharper and more useful: does the open skill ecosystem actually help agents on real-world tasks — and where, precisely, are its limits?
Skill Hub is our answer. It unifies four things that had only ever been attempted separately — aggregation, curation, matching, and real-world evaluation — inside a single framework, and ships the dataset, the fine-tuned models, and the full pipeline as open source.

Advantage 1 — Aggregation that actually spans the ecosystem
Most prior efforts drew from a single marketplace or, at most, two. That narrows what you can ever conclude about the ecosystem, because you've only seen a slice of it. Skill Hub instead aggregates across four distinct public discovery surfaces: direct crawls of 25,159 GitHub repositories, the major community marketplaces, Hugging Face datasets, and 19+ curated awesome-lists.
The difference is not cosmetic. Crawling source repositories directly — rather than reading marketplace metadata about them — recovers the bundled scripts, executable assets, and provenance that determine whether a skill is genuinely useful. The result is a raw pool of 800k+ SKILL.md files: the broadest, most source-diverse aggregation of the open skill ecosystem assembled to date, and the foundation everything else is built on.
Advantage 2 — Curation that's deterministic, layered, and auditable
Raw scale is a liability, not a feature. Half a million files are dominated by duplicates, broken stubs, and skills that look plausible but do nothing. Turning that into something an agent can rely on requires a curation process that is rigorous and reproducible. Skill Hub's pipeline runs eight deterministic stages across four phases — bit-for-bit replayable, with the rejection count at every stage published.

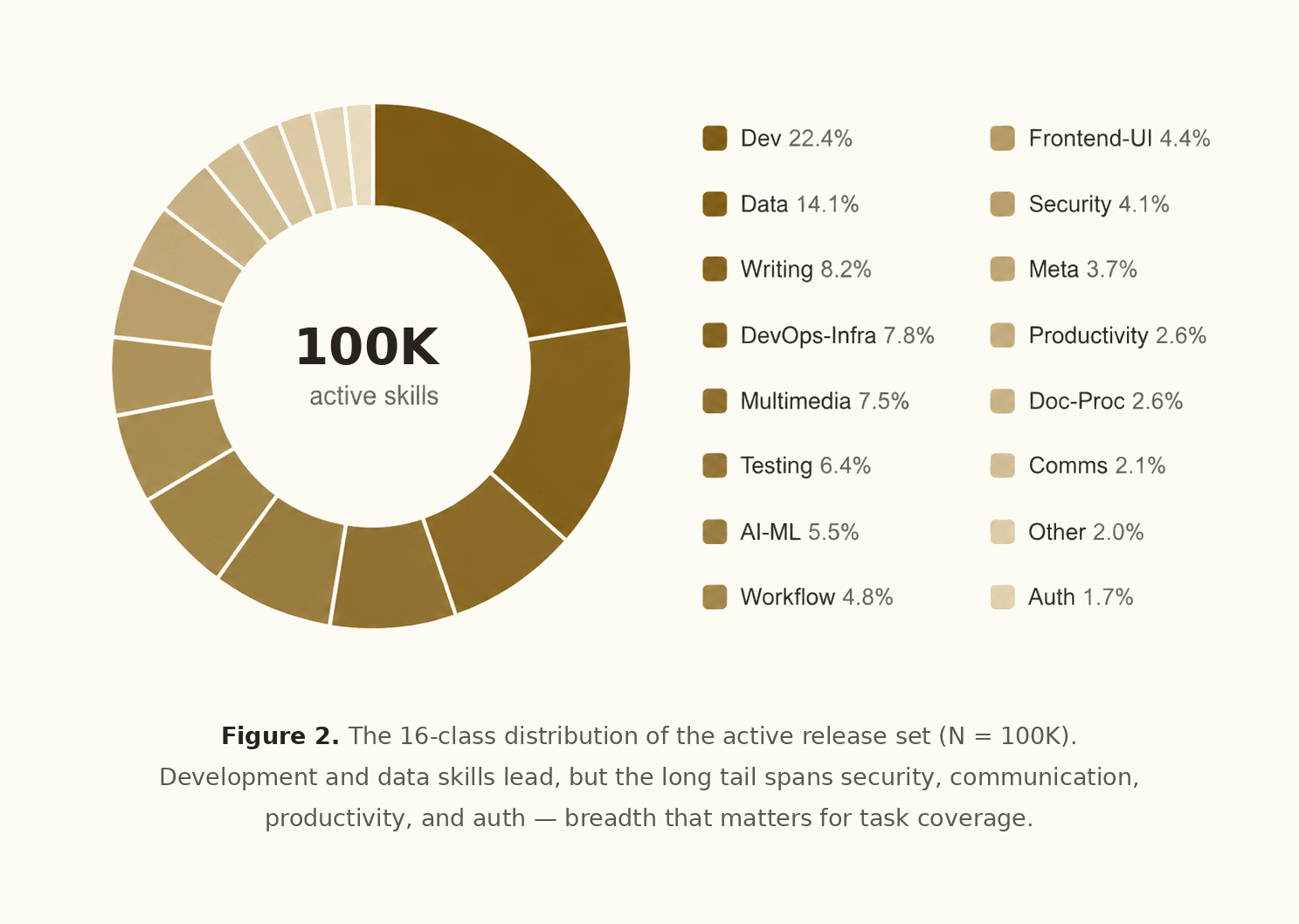
The quality model is deliberately three-facet and orthogonal — utility, robustness, and safety — rather than a long checklist where one strong dimension drags the rest up by halo effect. We verified that independence directly, and back it with 19 flags acting as hard gates and soft signals. What comes out the other end is 100k curated skills: broadly sourced, quality-tiered, and spread across 16 domains, with a clean audit trail from raw file to final corpus.
Every claim is traceable. The corpus, the per-stage rejection counts, the quality framework, and the license audit are all published — so the curation isn't a black box you have to trust, it's a pipeline you can re-run.
Advantage 3 — Matching tuned for skills, not generic text
A curated library is only useful if the right skill reaches the agent at the right moment. Generic, off-the-shelf retrieval treats a SKILL.md like any other document — and misses, because skills have structure and intent that general embeddings don't capture. Skill Hub ships a matching stack fine-tuned on the corpus itself: a tuned Qwen3-Embedding model for recall, a tuned Qwen3-Reranker for reordering, an LLM selector for the final pick, and an optional query rewriter.
Purpose-built retrieval pays off measurably. On the Skill Hub pool, the stack reaches a Hit@1 of 0.720 — a +10.7pp improvement over a strong naive retrieval baseline (0.613), with Recall@10 up +2.7pp. Better matching means the agent spends its context budget on the few skills that matter instead of drowning in near-misses.
Advantage 4 — Evaluation on real tasks, across real conditions
This is where Skill Hub departs most sharply from earlier work. Prior evaluations leaned on hand-picked oracle skills, or ran inside simulators, or tested a single execution harness. Each tells you something — but none tells you whether community skills help a real agent under varied deployment conditions.
We evaluated across a deliberately wide grid. Our paper reports the three primary real-world benchmarks — SkillsBench (deterministic-verifier tasks across 11 real domains), GDPVal (220 real economic tasks), and QwenClawBench (a real user distribution). The blog goes further, adding a fourth security benchmark (Cybench) and the full per-configuration breakdown that didn't fit in the paper. Every run spans two independent SKILL.md harnesses (OpenClaw and Raven) and multiple backbones, from open models (Qwen-27B and Qwen-397B) to a frontier check on Claude Opus.
The headline result: integrating Skill Hub consistently improves agent performance, with no significant regressions. Every one of the four benchmarks improved by a statistically significant margin — measured against task-level clustered standard errors.
Benchmark | What it measures | Pooled gain |
|---|---|---|
SkillsBench | 11 real domains, deterministic verifier | +7.5 ± 2.4 pp |
Cybench | Security tasks | +4.0 ± 1.4 pp |
QwenClawBench | Real user distribution | +2.8 ± 0.7 pp |
GDPVal | 220 real economic tasks | +1.5 ± 0.5 pp |
Because the paper could only summarize, the most useful detail — that gains hold under every harness and model combination, not just on average — never made it in. Here it is. On SkillsBench, each of the two harnesses and both model sizes improves once skills are switched on, and the lift grows with model scale:
Harness × backbone | No-skill | + Skill Hub | Gain |
|---|---|---|---|
OpenClaw × Qwen-27B | 8.8 | 13.0 | +4.2 |
OpenClaw × Qwen-397B | 11.1 | 16.9 | +5.7 |
Raven × Qwen-27B | 10.0 | 16.5 | +6.5 |
Raven × Qwen-397B | 9.2 | 22.6 | +13.4 |
The averages understate the ceiling. On SkillsBench the pooled lift is +7.5pp (a relative +76%), but on the strongest pairing — Raven × Qwen-397B — scores jumped from 9.2 to 22.6, a +146% gain peak +146%. Measured by overall task-success rather than pass@1, the best configuration climbed from 10% to 29% (+178%) once skills were switched on — nearly tripling completed tasks. And the matching stack does its share of the work: recall that it lands the right skill at Hit@1 = 0.720, so these gains come from skills the agent could actually find.
The interesting part: where the gains stop
A capability layer you can deploy responsibly has to come with its limits drawn, not just its wins advertised. Our operational analysis surfaced two boundaries that govern how much community skills can help.
The first is a coverage boundary: gains track how densely the curated corpus covers the task at hand. Where the library is dense, agents improve sharply; where a task falls into a thin region of the corpus, there's simply less to retrieve. The second is a harness execution-depth boundary: the same skill delivers more when the harness around it can execute deeply enough to use it — the loader and runtime are part of the capability, not neutral plumbing.
Naming these boundaries is the point. They turn "skills help" into a usable model of when and how much they help — exactly what you need to deploy community skills as a dependable capability source rather than a hopeful add-on.
Open by construction
Everything described here is released. The 96,401-skill curated dataset, the fine-tuned embedding-plus-reranker matching stack, and the complete curation, training, and evaluation code are all open — every skill license-audited, 100% OSI-compliant, and free to redistribute commercially. Every skill exposes its source: install your own version privately, or grow a new one from your own memory with a single sentence.
Skill Hub takes a scattered, redundant, uneven ecosystem and turns it into a foundation with its effectiveness measured and its edges mapped. That's what it takes for community skills to become a reliable source of capability for LLM agents — not just an abundant one.
Benchmark figures are drawn from the controlled skills-vs-no-skills evaluation across 4 model pairings, 4 benchmarks, and 3 repetitions each; SkillsBench shows a pooled +7.5pp average pass-rate lift (relative +76%), peaking at +146% on the strongest pairing. All gains reported are statistically significant against task-level clustered standard errors.
The open SKILL.md ecosystem now numbers in the millions of files. We aggregated it, curated it, learned to match it to real tasks — and then stress-tested whether community skills actually make agents better. Here's what we built, and what the benchmarks showed.
Skill Hub Research · 10 min read · Fully open-source, audited, and 100% OSI-compliant
Large language models are increasingly the engine of agents that plan and execute long-horizon work rather than answer isolated questions. Yet even the strongest frontier models still complete these tasks unreliably — and that gap is hard to close with a bigger base model alone. One of the most promising answers is to externalize capability into modular units that an agent can load at inference time.
Agent skills — SKILL.md files — do exactly this: they package reusable procedural knowledge into units an agent can pull in on demand. A community ecosystem of these skills has formed remarkably fast, with public repositories now accumulating skills by the million. In principle, that's an enormous, open source of capability for any agent.
In practice, abundance hasn't translated into reliability. Community skills are scattered across channels, heavily redundant, wildly uneven in quality, and occasionally carry safety risk. The question that mattered to us was never "how many skills exist?" It was sharper and more useful: does the open skill ecosystem actually help agents on real-world tasks — and where, precisely, are its limits?
Skill Hub is our answer. It unifies four things that had only ever been attempted separately — aggregation, curation, matching, and real-world evaluation — inside a single framework, and ships the dataset, the fine-tuned models, and the full pipeline as open source.
Advantage 1 — Aggregation that actually spans the ecosystem
Most prior efforts drew from a single marketplace or, at most, two. That narrows what you can ever conclude about the ecosystem, because you've only seen a slice of it. Skill Hub instead aggregates across four distinct public discovery surfaces: direct crawls of 25,159 GitHub repositories, the major community marketplaces, Hugging Face datasets, and 19+ curated awesome-lists.
The difference is not cosmetic. Crawling source repositories directly — rather than reading marketplace metadata about them — recovers the bundled scripts, executable assets, and provenance that determine whether a skill is genuinely useful. The result is a raw pool of 800k+ SKILL.md files: the broadest, most source-diverse aggregation of the open skill ecosystem assembled to date, and the foundation everything else is built on.
Advantage 2 — Curation that's deterministic, layered, and auditable
Raw scale is a liability, not a feature. Half a million files are dominated by duplicates, broken stubs, and skills that look plausible but do nothing. Turning that into something an agent can rely on requires a curation process that is rigorous and reproducible. Skill Hub's pipeline runs eight deterministic stages across four phases — bit-for-bit replayable, with the rejection count at every stage published.
The quality model is deliberately three-facet and orthogonal — utility, robustness, and safety — rather than a long checklist where one strong dimension drags the rest up by halo effect. We verified that independence directly, and back it with 19 flags acting as hard gates and soft signals. What comes out the other end is 100k curated skills: broadly sourced, quality-tiered, and spread across 16 domains, with a clean audit trail from raw file to final corpus.
Every claim is traceable. The corpus, the per-stage rejection counts, the quality framework, and the license audit are all published — so the curation isn't a black box you have to trust, it's a pipeline you can re-run.
Advantage 3 — Matching tuned for skills, not generic text
A curated library is only useful if the right skill reaches the agent at the right moment. Generic, off-the-shelf retrieval treats a SKILL.md like any other document — and misses, because skills have structure and intent that general embeddings don't capture. Skill Hub ships a matching stack fine-tuned on the corpus itself: a tuned Qwen3-Embedding model for recall, a tuned Qwen3-Reranker for reordering, an LLM selector for the final pick, and an optional query rewriter.
Purpose-built retrieval pays off measurably. On the Skill Hub pool, the stack reaches a Hit@1 of 0.720 — a +10.7pp improvement over a strong naive retrieval baseline (0.613), with Recall@10 up +2.7pp. Better matching means the agent spends its context budget on the few skills that matter instead of drowning in near-misses.
Advantage 4 — Evaluation on real tasks, across real conditions
This is where Skill Hub departs most sharply from earlier work. Prior evaluations leaned on hand-picked oracle skills, or ran inside simulators, or tested a single execution harness. Each tells you something — but none tells you whether community skills help a real agent under varied deployment conditions.
We evaluated across a deliberately wide grid. Our paper reports the three primary real-world benchmarks — SkillsBench (deterministic-verifier tasks across 11 real domains), GDPVal (220 real economic tasks), and QwenClawBench (a real user distribution). The blog goes further, adding a fourth security benchmark (Cybench) and the full per-configuration breakdown that didn't fit in the paper. Every run spans two independent SKILL.md harnesses (OpenClaw and Raven) and multiple backbones, from open models (Qwen-27B and Qwen-397B) to a frontier check on Claude Opus.
The headline result: integrating Skill Hub consistently improves agent performance, with no significant regressions. Every one of the four benchmarks improved by a statistically significant margin — measured against task-level clustered standard errors.
Benchmark | What it measures | Pooled gain |
|---|---|---|
SkillsBench | 11 real domains, deterministic verifier | +7.5 ± 2.4 pp |
Cybench | Security tasks | +4.0 ± 1.4 pp |
QwenClawBench | Real user distribution | +2.8 ± 0.7 pp |
GDPVal | 220 real economic tasks | +1.5 ± 0.5 pp |
Because the paper could only summarize, the most useful detail — that gains hold under every harness and model combination, not just on average — never made it in. Here it is. On SkillsBench, each of the two harnesses and both model sizes improves once skills are switched on, and the lift grows with model scale:
Harness × backbone | No-skill | + Skill Hub | Gain |
|---|---|---|---|
OpenClaw × Qwen-27B | 8.8 | 13.0 | +4.2 |
OpenClaw × Qwen-397B | 11.1 | 16.9 | +5.7 |
Raven × Qwen-27B | 10.0 | 16.5 | +6.5 |
Raven × Qwen-397B | 9.2 | 22.6 | +13.4 |
The averages understate the ceiling. On SkillsBench the pooled lift is +7.5pp (a relative +76%), but on the strongest pairing — Raven × Qwen-397B — scores jumped from 9.2 to 22.6, a +146% gain peak +146%. Measured by overall task-success rather than pass@1, the best configuration climbed from 10% to 29% (+178%) once skills were switched on — nearly tripling completed tasks. And the matching stack does its share of the work: recall that it lands the right skill at Hit@1 = 0.720, so these gains come from skills the agent could actually find.
The interesting part: where the gains stop
A capability layer you can deploy responsibly has to come with its limits drawn, not just its wins advertised. Our operational analysis surfaced two boundaries that govern how much community skills can help.
The first is a coverage boundary: gains track how densely the curated corpus covers the task at hand. Where the library is dense, agents improve sharply; where a task falls into a thin region of the corpus, there's simply less to retrieve. The second is a harness execution-depth boundary: the same skill delivers more when the harness around it can execute deeply enough to use it — the loader and runtime are part of the capability, not neutral plumbing.
Naming these boundaries is the point. They turn "skills help" into a usable model of when and how much they help — exactly what you need to deploy community skills as a dependable capability source rather than a hopeful add-on.
Open by construction
Everything described here is released. The 96,401-skill curated dataset, the fine-tuned embedding-plus-reranker matching stack, and the complete curation, training, and evaluation code are all open — every skill license-audited, 100% OSI-compliant, and free to redistribute commercially. Every skill exposes its source: install your own version privately, or grow a new one from your own memory with a single sentence.
Skill Hub takes a scattered, redundant, uneven ecosystem and turns it into a foundation with its effectiveness measured and its edges mapped. That's what it takes for community skills to become a reliable source of capability for LLM agents — not just an abundant one.
Benchmark figures are drawn from the controlled skills-vs-no-skills evaluation across 4 model pairings, 4 benchmarks, and 3 repetitions each; SkillsBench shows a pooled +7.5pp average pass-rate lift (relative +76%), peaking at +146% on the strongest pairing. All gains reported are statistically significant against task-level clustered standard errors.
You may also like these
Related

Introducing mRAG: How EverOS Retrieves What Actually Matters
mRAG, multimodal, multimodal retrieval, RAG

Introducing Self-Evolving Agent Memory: How EverOS Helps Your AI Agents Learn from Experience
Self-Evolving Agent Memory, Agent Memory, Self-Evolving, Agent Skills, Agent Cases

Breaking the 100M Token Limit: MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
long term memory, RAG, context, ai agent, OpenClaw, sparse attention, transformers, LLM, KV cache

EverOS: SOTA Results Across Four Memory Benchmarks and What It Means for LLM Agents
EverOS, long term memory, RAG, context, LoCoMo, LongMemEval, PersonaMem
Skill Hub: a measured foundation for community-powered agents
Skill Hub turns the scattered open SKILL.md ecosystem into a curated, searchable, and benchmarked capability layer for LLM agents — aggregating 800k+ raw skills, releasing 100k audited OSI-compliant skills, and showing statistically significant gains across four real-world benchmarks.
EverMind researchers
About 3 minutes to read

© 2026 EverMind Team.
© 2026 EverMind Team.
© 2026 EverMind Team.